
Forståelse og Kodning af Neuralt Netværk fra bunden
Et neuralt netværk er en sammesætning af neuroner. Det tager flere input. Som går gennem flere gemte lag.
Grundstenen for neurale netværk er en Perceptron. En perceptron tager flere input og producere et output.
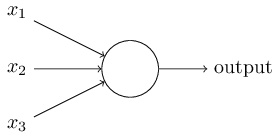
Tag ovenstående illustration af en Perceptron ville have 3 input værdier kaldet x1, x2, x3 og en vægt til hvert input kaldet w1, w2, w3. Samtidig har en Perceptron en Bias som er en værdi vi kan bruge til at tilpasse funktionen, så vi kan opnå et bedre fit på dataen med vores forudsigelse. Bias har en vægt af 1. Så vi bruger Bias værdien direkte uden at blive vægtet.
Dvs. hvis vi skriver denne Perceptrons linære repræsentation får vi (w1x1 + w2x2 + w3x3 + 1b), hvor vi kan sætte et threshold på 0 for, at udregne resulatet, så vi får w1x1+w2x2+w3x3+1b>0.
Perceptrons er linære og blev viderudviklet til Kunstige Neuroner som gør brug af ikke-linære aktiverings funktioner.
Aktiverings Funktioner
Der findes flere aktiverings funktioner som f.eks. nedenstående:
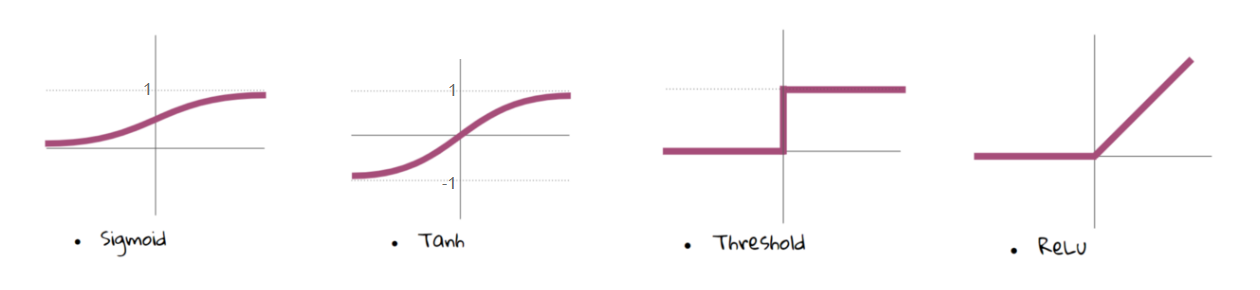
Aktiverings funktioner giver os muligheden for at estimere eller tilpasse ikke linære eller komplekse funktioner for at få et bedre aktiverings punkt for neuronen.
Forward Propagration, Back Propagration og Epochs
Når man får netværket til at udregne resultatet kaldes det Forward Propagation.
Back Propagation bruges til at indstille vægtene og bias værdierne på baggrund af fejlmængden/tabet også kaldet Cost Function af vores Output lag.
En iteration af Forward og Back Propagration er kaldet en trænings iteration aka Epoch.
Multi-layer perception (MLP)
MLP kan have flere gemte lag imellem input og output lagene. Som åbner en masse muligheder for mere avanceret og komplekse modeller.
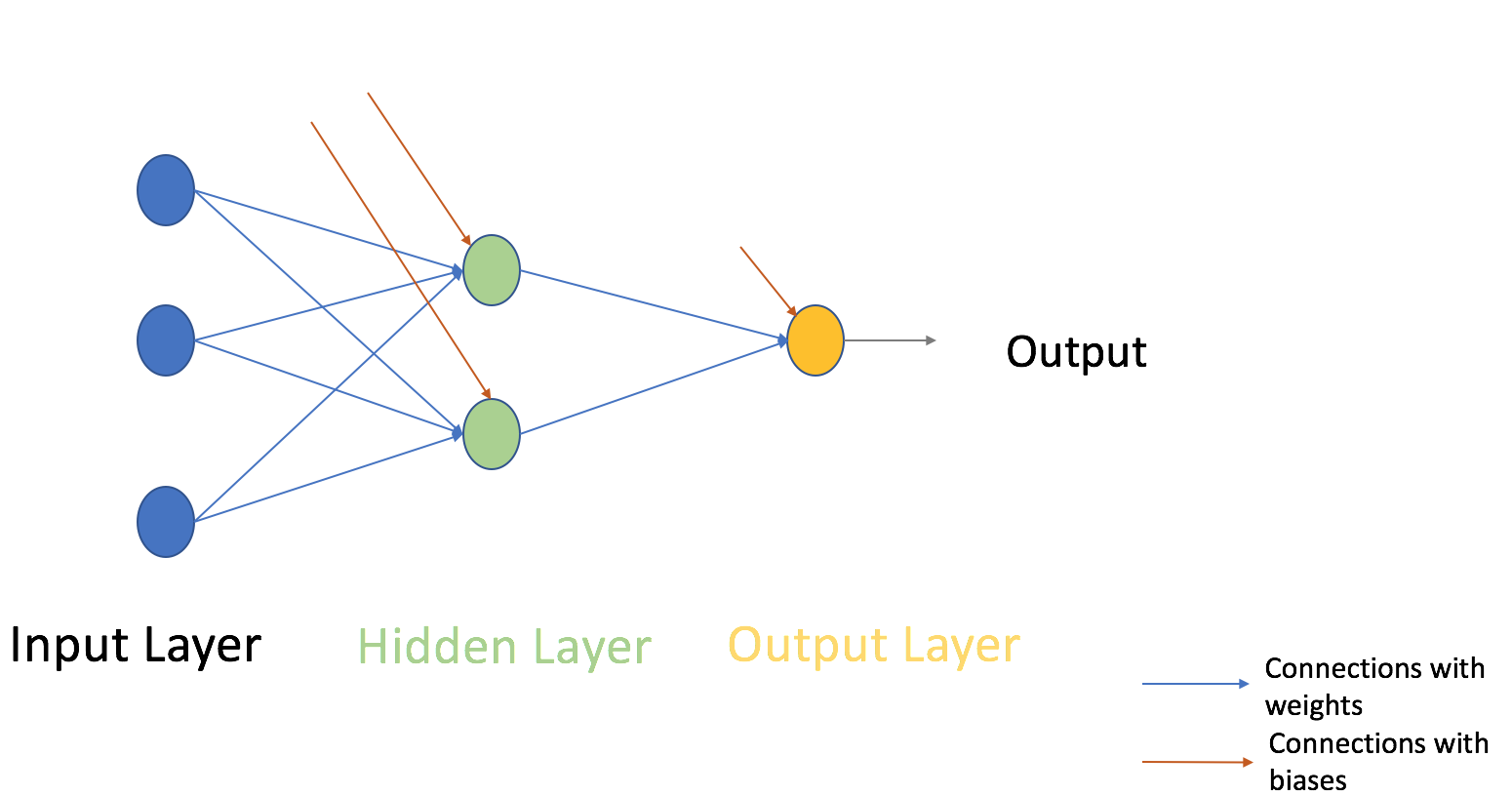
MLP er fuldt forbundet hvilket betyder, at alle noder I hvert lag undtagen input og output – lagene er fuldt fobundet med hver node i tidligere og næste lag.
Gradient Decent
Er en træningsalgoritme findes to varianter
- Full Batch Gradient Descent (Full Batch)
- Stochastic Gradient Descent (SGD)
Full Batch: Bruger hele træningsættet per vægt. F.eks. man har 10 datapunkter og 2 vægte. Der bruger den alle 10 punkter til at beregne w1 og igen alle 10 punkter til w2.
SGD: Bruger 1 til flere men aldrig hele sættets datapunkter til en vægt. Dvs. At vi bruge måske punkt 1 til vægt 1 og derefter punkt 1 til vægt 2. Vi kan også bruge flere punkter til hver vægt.
Trænings algoritmer er brugt til at minimere Cost funktionen.
Trin for trin hvordan et Neuralt Netværk fungere med Full Batch
Hvis vi tager følgende netværk
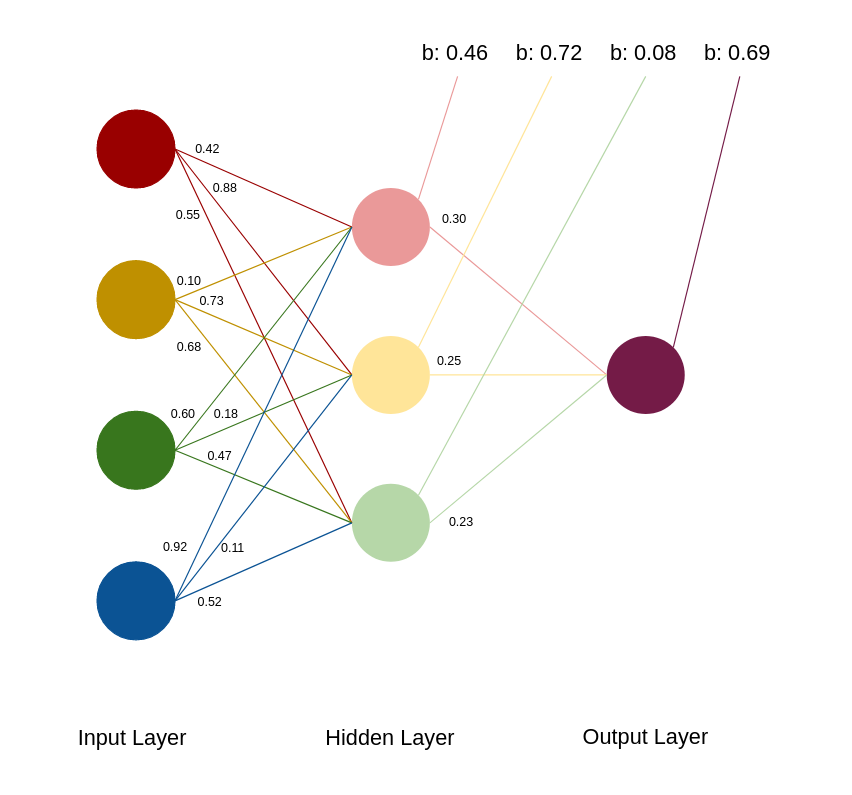
Hvert tal ud fra en streg er en vægt og hver streg til en b - værdi er nodens bias.
Trin 1. Vi starter med at indsætte vores 3 input, de 3 resultater og vælger nogle tilfælidge vægte og bias.
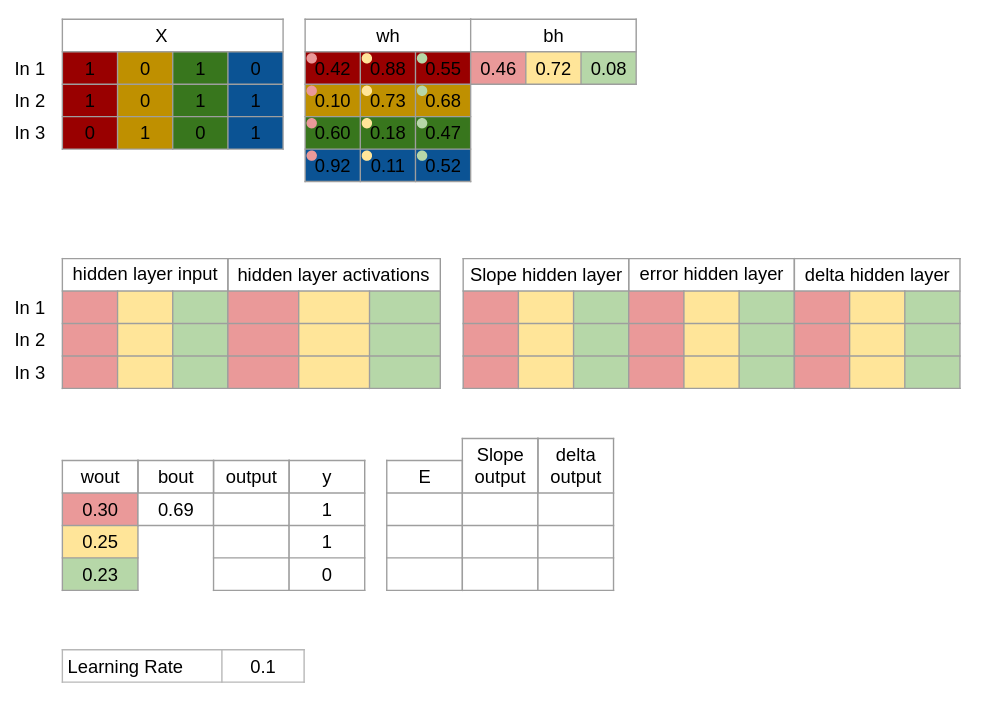
X = Inputs y = Outputs
wh = Wheights for Hidden layer bh = Bias for Hidden layer
wout = Weights for Output layer bout = Bias for Output layer
Trin 2 Vi udregner inputværdierne til Hidden layer, som gøres ved at gange inputs med vægtene plusset med vores bias.
F.eks. ved første input runde(In 1) som har værdierne 1, 0, 1, 0. Der tager vi værdierne og ganger med hver vægt(0.42, 0.10, 0.60, 0.92) til første gemte node(Rød) og samler i et total som vi plusser med vores bias for første gemte node(Rød) som giver os vores input til den node for første runde.
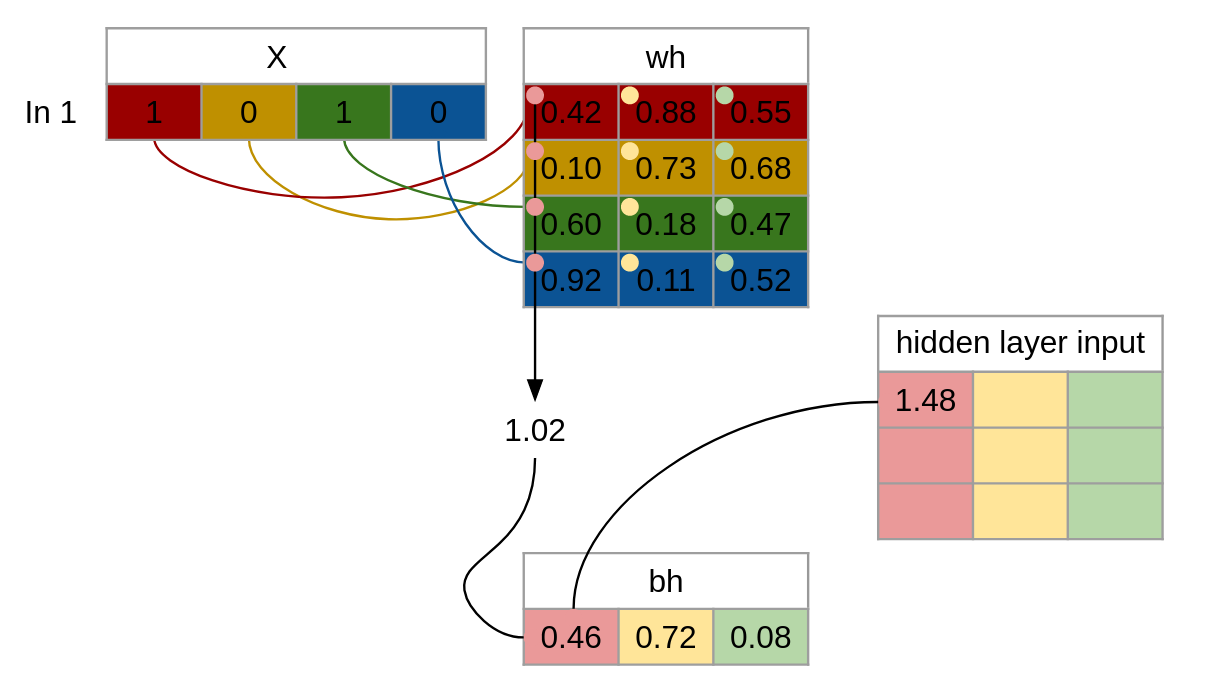
Så vi får for at beregne alle værdier: hidden_layer_input = matrix_dot_product(X,wh) + bh
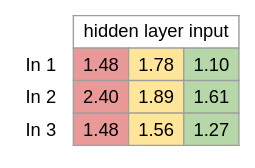
Trin 3 Vi bruger Sigmoid som ikke-linær transformations funktions(aktiverings funktion) og den kan beskrives som: 1/(1 + exp(-x)) Exp() står for eksponentiel funktion som python har. Det gør vores funktion også kan skrives som: 1/(1 + e^-x) I tilfælde af man ikke har exp() til rådighed.
Dette gøres for hver værdi, så de alle er mellem 0 og 1.
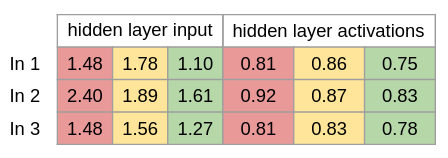
Dette skriver vi som: hidden_layer_activations = sigmoid(hidden_layer_input)
Trin 4 Vi laver så trin 2 og 3 for output i stedet.
Så vi finder først inputtet til output laget ved at gange aktiveringerne i det gemte lag med vægtene til output laget plusset med bias for output laget: output_layer_input = matrix_dot_product(hidden_layer_activations * wout) + bout
Derefter transformere vi tallet igen ved hjælp af vores aktiverings funktion for at få et tal mellem 0 og 1. output = sigmoid(output_layer_input)
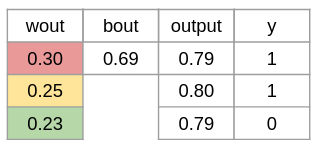
Tring 5 Vi beregner graden af fejl ved at trække output fra vores kendte svar: E = y-output
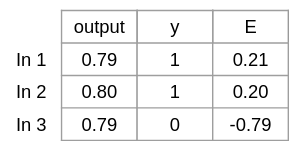
Trin 6 Vi beregner nu hældingen / derivatives sigmoid for hver aktivering. Som er hvor følsom funktionen er overfor ændringer på det givet punkt. Slope siger noget om grafens position. Et positivt tal betyder den er stigende fra venstra mod højte. Et negativt tal betyder den er faldende fra venstre mod højre. Jo stærkere positiv eller negativ desto stejlere er grafen i det punkt. Og derfor fortæller den os meget hurtigt, hvor følsom funktionen er lige der.
Derivatives Sigmoid kan skrives som: x * (1 – x) Dette gøres for alle vores akriverings punkter. Dvs. båede output og hidden_layer_activations.
Slope_hidden_layer = derivatives_sigmoid(hidden_layer_activations) Slope_output = derivatives_sigmoid(output)
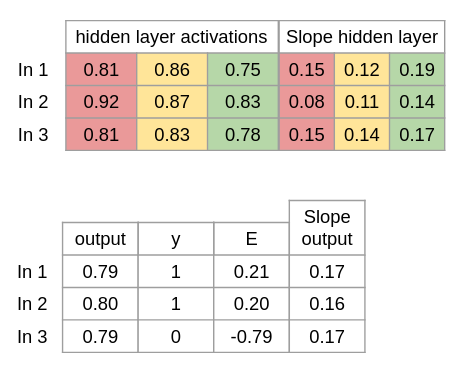
Trin 7 Nu beregner vi delta for ouput laget som er den mængde vi skal tilpasse med. Dette gør vi ved at gange fejlgraden med hældningen for hvert output. d_output = E * Slope_output
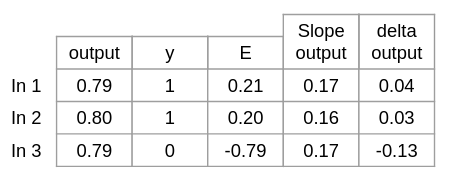
Trin 8 Vi beregner så fejlgraden i det gemte lag, da ændringerne skal høres tilbage igennem hele netværket.
Dette gør vi ved at gange ændringen i output laget med vægtene til de tidligere neuroner i det gemte lag. Error_at_hidden_layer = matrix_dot_product(d_output, wout.Transpose)
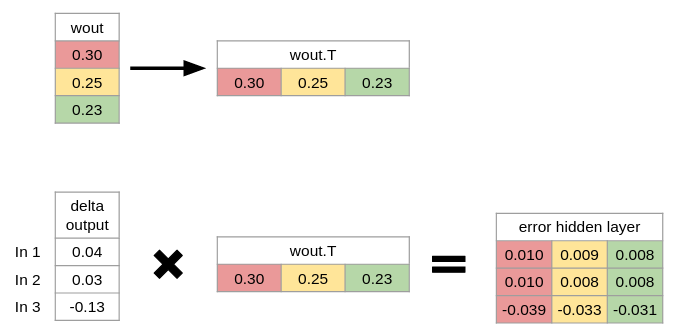
Bemærk det er nødvendigt at lave wout om til wout.T, da hvert inputs ændring i output skal ganges på hver vægt til tidligere neuroner.
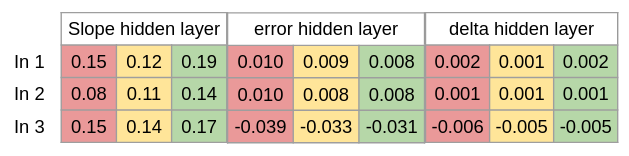
Trin 9 Der skal nu beregnes ændringerne til det gemte lag. Det gør vi ved at gange fejlgarden i det gemte lag med hældningerne i det gemte lag.
d_hiddenlayer = Error_at_hidden_layer * Slope_hidden_layer
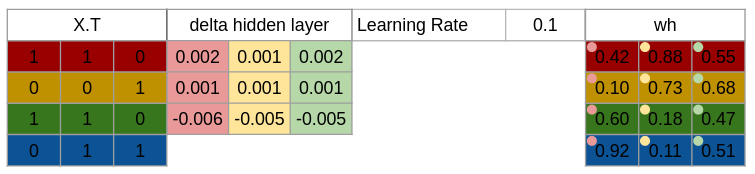
Trin 10 Så opdatere vi vægtene for både output og hidden layer. Det gør vi ved, at gange de respektive aktiveringsværdier med forskels værdierne ganget en valgt læringsrate og ligge det oveni de nuværende vægte, så vi får: wh = wh + matrix_dot_product(X.Transpose, d_hiddenlayer) * learning_rate
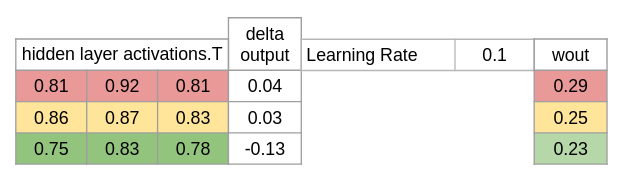
wout = wout + matrix_dot_product(hidden_layer_activations.Transpose, d_output) * learning_rate
Trin 11 Vi mangler kun nu at indstille bias værdierne. Det kan gøres ved at vi tager summen af en kolonne fra en tabel med forskelsværdier(delta) og summere den og ganger med vores læringsrate og ligger oveni den eksisterende tilhørende bias.
Dvs. vi får noget lignende: bh = bh + sum(d_hiddenlayer, axis=0) * learning_rate

bout = bout + sum(d_output, axis=0) * learning_rate

Vi burde nu have en total model der ser ligeledes sådan ud:
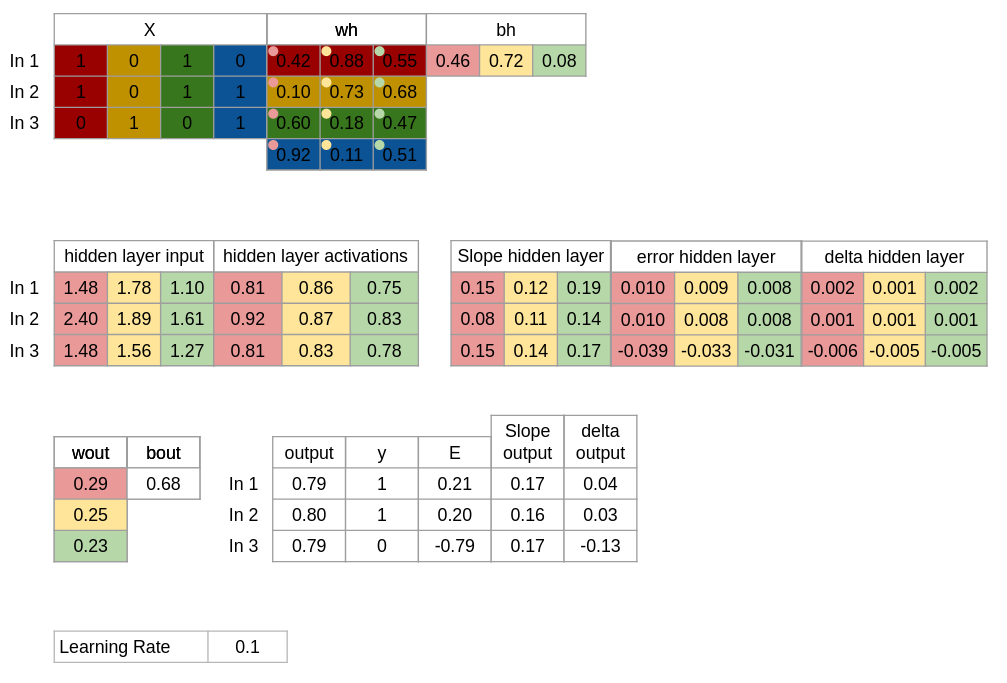
Vi har nu kørt en trænings iteration også kaldet Epoch. Bemærk at Trin 1 - 4 er kendt som “Forward Propagatoin” og Trin 5 - 11 er kendt som “Backward Propagation”.
Alt det forrige kan gøres i kode: