
Forståelse af RNN
Hvad er RNN?
RNN står for Recurrent Neural Network og er kommet til pga. behovet for at håndtere varieret typer og længder af båede input og output værdier. Dvs. RNN kan håndtere sekvens input aka. den kan holde en gennemgående relation til forrige inputs i en sekvens af data for at skabe et samlet output. Dette kan være et time series problem, hvor tidspunktet / rækkefølgen for dataen i sekvensen har noget at gøre med den næste værdi. F.eks. i en sætning, som “Jeg køber ind” har rækkefølgen af bogstaverne / ordene stor betydning for forståelsen af sætningen.
Hvordan ser det ud?
Hvis vi kigger på MLP(Multi-layer Peceptron) som kan have flere gemte lag. Hvor vi teknisk set kan smide, hvert ord ind fra en sekvens og få et output der afhænger af rækkefølgen.
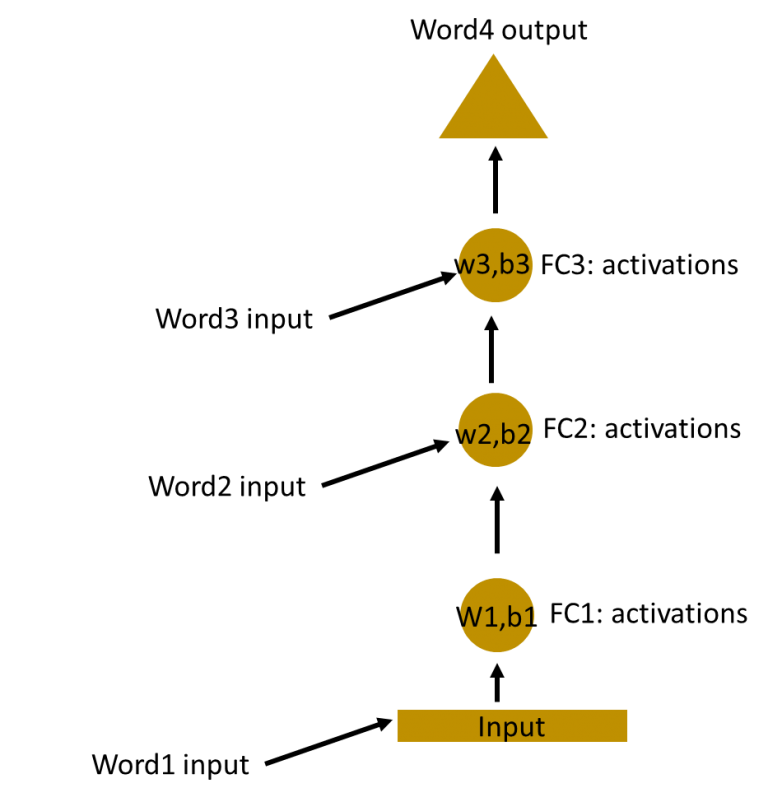
Men da alle deres vægte og bias er inviduelle kan vi ikke kombinere dem. For at kunne kombinere dem og få et lag skal de have ens vægt og bias. Grunden til vi vil kombinere dem er, at kunne have et lag med en given “historik” af tidligere inputs.
Så hvis vi kombinere de 3 lag får vi en Recurrent Neuron:

Som kan ses på billedet kan den tage hele sætningen som et input. Da vi kan holde værdierne internt i den nye block. Da den bare er en kombination af de gemte lag, som stadig relatere til hinanden i form af en lang kæde.
Hvis man folder RNN’en ud vil man se det som beskrevet ovenfor:
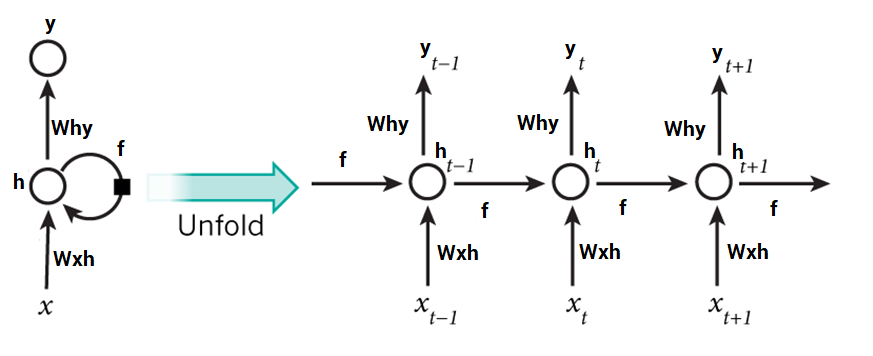
Hvor x er input og y er output. t står for nuværende time step. Et time step er på et tidspunkt i rækkefølgen. F.eks. hvis vi har 4 bogstaver som input {h, e, l, l} vil det første time step være for ‘h’.
I RNN tager vi tidligere udregnet tilstande for vores gemte lag med i overvejelsen. Dvs. vi tager vores tidligere udregnet tilstand og ganger med vores vægte i vores gemte lag plusset vores bias og ligger oveni vores input x ganget med vægtene for input’sne. Dette propper vi ind i en aktiverings funktion som f.eks. tanh. Til sidst får vi noget der kan skriver som: ht = tanh((Whh * ht-1 + bias) + (Wxh * xt))
Når man har beregnet den nuværende tilstand, kan man udregne resultatet som er vægten for outputtet ganget med den nuværende tistand, så vi kan sige: yt = Why * ht
Trin for trin
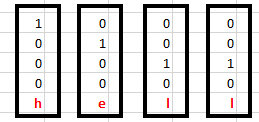
Givet vi har inputs {h, e, l, l} som er 1-enkodet som set ovenfor i en bogstavliste af {h, e, l, o} og vi prøver at forudse det næste bogstav i h-e-l-l-?, som gerne skulle give “o” og forme hallo.
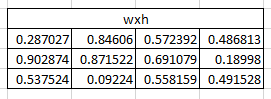
Og givet de tilfældige vægte for vægtene fra input til det gemte lag. Som set ovenfor.
Trin 1
Ved første input ganges vægtene med inputtet indtil Recurrent Neuronen. Inputtet er Xt og vægtene for inputtet er Wxh.

Trin 2 Ved Recurrent Neuronen har vi Whh som en vægt på 0,427043 og en bias på 0,56700.
For første input er den tidligere tilstand [0, 0, 0].
Så ved: whh * ht-1 + bias Bliver alle 3 beregninger lig med bias.

Trin 3 Så kan vi beregne den nuværende tilstand med: ht = tanh((Whh * ht-1 + bias) + (Wxh * Xt))
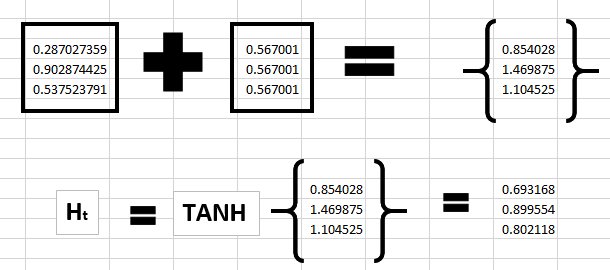
Trin 4 Første tilstand udregnet bliver nu “ht-1” og vi beregner nu for “e” som så er vores Xt.
Vi bruger samme beregning som i “Trin 3”.
Så for “Whh * ht-1 + bias”:

Og for “Wxh * xt”:

Trin 5 Så beregner vi tilstanden / ht for “e”.
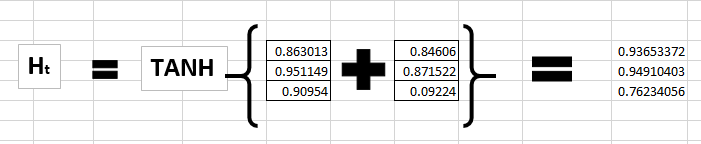
Nu med et nyt ht-1 som bliver taget med i næste beregning forsætter vi sådan.
Trin 6 For hver tilstand vil RNN’et producere et output. Det kan beregnes som yt med: yt = Why * ht
Så hvis vi beregner outputtet for “e”.

Trin 7 Man kan beregne sandsynligheden for et bostav i vores bogstavsliste ved brug af softmax funktionen.
Softmax er brugt til at udregne sandsynligheden for en række givne klasser. Softmax er også kendt som normalized exponential function. Softmax udgiver en probalility distribution af “K” sandsynligheder som svarende til “K” reele tal i input vektoren.
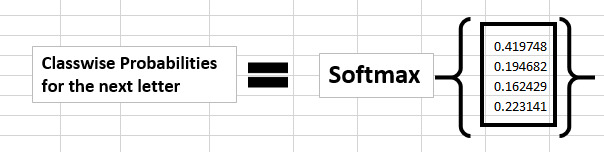
Som kan ses er den største sandsynlighed for næste bogstav “h”, men det er ikke korrekt. Dette er fordi vi ikke har lavet noget back propagation endnu og har ikke trænet netværket.
Back propagation i et Recurrent Neural Network
I et RNN ved forward propagation bliver hvert input flyttet fremad ved hvert time step.
Ved back propagation går vi tilbage i tiden igennem time step’sne og ændre vægtene. Derfor bliver det kaldt Back Propagation Through Time (BPTT).
Hvis vi igen kigger på RNN udfoldet kan det nemmere ses:
Man bruger cross entropy loss til at beregne fejlmængden. Cross entropy loss er en effektiv måde, at beregne afstanden til den optimale funktions resultat. Det er en måde, at sige, hvis vi har den optimale funktion som giver resultatet “y” som er vores rigtige værdi, vi beregner så, hvor langt vi er fra den funktion.
Så hvis yt er vores resultat vi har forudsagt og ytr er vores rigtige resultat, beregner man fejlmængden med cross entropy loss:
Fejlen ved et time step: Et(ytr,yt) = -ytr * log(yt)
Da et trænings eksempel oftest er en sekvens eller i dette eksempel et ord. Vil den totale fejlmængde være, hvert time steps fejlmængde summeret: E(ytr,yt) = -sum(ytr * log(yt))
Hver gradient for hvert time step i det udfoldet netværk bliver beregnet i forhold til vægtene og da de har samme vægte kan de ligges sammen som en total gradient.
Vægtene er så opdateres for båede recurrent neuronen og de tætte lag.
Et udfoldet RNN ligner et NN både i arkitekturen og i back propagation’en, bortset fra vi ligger alle gradienter sammen fra alle steps i stedet.
I et RNN med flere hundrede og måske tusinde bliver det udfoldet netværk meget stort og efter ens logik meget svær, at udregne tilpasningerne. Dette er ikke helt sandt, men jeg kan ikke forklare hvorfor.
Vanishing og Exploding Gradients - problemet
RNN kan få 2 problemer ved længere afhængige værdier. F.eks. en lang sætning der handler om en mand eller beskriver ham. Vil de sidste beskrivelser relatere til manden og ikke et andet objekt man omtaler i sætningen.
Her vil man bruge chain rule men, hvis en af værdierne eller “gradients” nærmede sig 0 ville alle andre også hurtigt nærme sig nul pga. den eksponentielle kæde og netværket ville ikke rigtig lære noget af det. Dette er kaldet Vanishing gradient problemet.
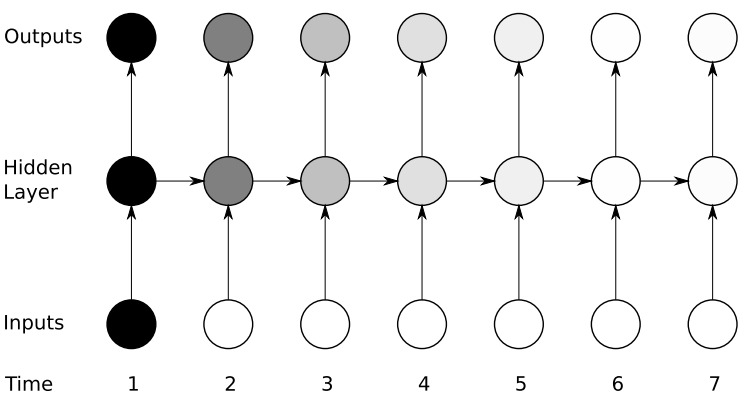
Som kan ses på billedet er, at Vanishing Gradient problemet er basicly, at de tidligere features bliver visket ud og kan ikke ses i enden. Medmindre man gør noget.
Hvor modsat, hvis nogle af gradients værdierne var høje, vil de meget hurtigt alle blive høje igen grundet det eksponentielle. Dette kan dog nemt løses ved at cutte værdierne ved et givet threshhold.
RNN lider derfor af Vanishing gradient problemet ved lange afhængige inputs.
RNN bliver også utroligt svært at træne ved længere sekvenser med afhængig værdier, da i parameterne i den udrollet RNN vil være rigtig mange der skulle udregnes og det bliver derfor en udfordring.
Arkitekturene LSTM(Long Short Term Memory) og GRU(Gated Recurrent Units) can blive brugt til at håndtere Vanishing Gradient problemet.