
Google Cloud - Vision
Hvad er Google Vision?
Google Vision er Google’s billede machine learning, som man lidt ligesom ML.NET’s AutoML prøvet, at finde den mest effektive model og kan trænes i skyen så meget som man føler passende, samt overføres direkte over i Google Cloud. Dette giver en høj fleksibilitet til, at kunne træne flere forskellige modeller samtidig og hurtigt uden, at have adgang til store servere eller stærke arbejdscomputere. Det giver mulighed for, at teste og eksperimentere med ens modeller og data. Men Vision kommer ikke kun med en pris i form af penge, men også en tilvænning af brugen af Google Cloud og dens begrænsninger.
Håndtering og tilpasning af data
Jeg brugte 49000 billeder med label fra samme kilde som KerasNumberRecognition eksperimentet.
Så det første man ser er, at man kan vælge billeder fra ens computer eller Google Cloud Storage(GCS). Men vælger man fra sin computer bliver man mødt med et maks. på 500 billeder af gangen, hvis de kan håndtere det. Jeg fandt så ud af, at man kunne uploade en .zip fil med alle billederne i og så kunne Google selv udpakke og indeksere billederne i filen. Men endnu engang er der problemer fordi, man kan ikke tilføje en .csv fil med alle mærkaterne til alle billederne efterfølgende, da de skal indeholder stier til, hvor billederne er på ens GCS. Jeg prøvede så, at lave hele .csv filen med GCS stier som pegede på .zip filen og de tilhørende billeder. Dette resulterede kun i en masse fejl omkring billederne ikke kunne findes.
Så da upload fra Googles egen side ikke er en mulighed fandt jeg ud af, at jeg kunne uploade billeder til GCS via. deres API, så jeg skrev et stykke python kode.
Fra Google Cloud kan man få en nøgle til ens konto som man gemmer på computeren, denne nøgle supplere man så til klienten. Man kan også nøjes med, at tilføje en ENVIRONMENT variable på ens maskine med nøglen, selvom jeg ikke fik den del til, at virke og var nød til, at finde andre måder.
Dette Python script virkede fint bortset fra, at med cirka 2 billeder uploadet per sekund står vi overfår, at vente i næsten 7 timer for 49000 billeder.
Det var så her jeg faldt over transfer jobs i Google Cloud. Disse transfer jobs, lod ens downloade et container images som kunne køres på Docker som agerede som et link til ens GCS. Man opsatte så jobbet på Google Cloud efter, at have konfigureret ens server og så kunne man synkronisere direkte til GCS. Der gik det en del hurtigere. Jeg kunne herefter lave en .csv fil med alle de rigtige GCS stier til hvert billede og mærkater. Her kunne jeg så uploade den .csv fil til Google Vision, som fandt alle billederne og tilføjede de rigtige mærkater.
Bemærk: Hvis man ikke i sin .csv fil specificere TRAIN, VALIDATE og TEST linjer, så bruger Google Vision automatisk et split der fordeles 80/10/10 procent givet førnævnte rækkefølge.
TIP: Jeg fandt ud af efter, at have brugt en .zip fil til billederne til Vision, at alle billederne havde nogle midlertidige GCS links som startede med et tidspunkt og en hashed værdi efterfulgt af det originale billede navn. Jeg kunne ikke se nogle af de her billeder på min GCS, men jeg havde en anelse om, at det var Vision ligeglad med. Så jeg lavede en ny .csv fil, med den hashed værdi osv. i starten af linket, efterfulgt af billede navnet og mærkater og uploadede den til Vision. Og rigtigt nok Vision trak alle de midlertidige filer fra det første projekt og indførte dem i det nye projekt dog den her gang med alle de rigtige mærkater.
Træning via. Google Vision
Jeg kunne nu begynde, at eksperimentere med Visions træning. Måden man træner med Vision på er ganske simpel efter man har fået dataene rigtig ind. Man går bare under “Train” og starter en ny model. Google giver så nogle muligheder for, hvor hurtig eller præcis den skal være for, at den passer bedst til ens problem, så jeg valgte, at gå efter højeste præcision, da det var det jeg ville teste. Den foreslog mig for mit datasæt, at den skulle bruge 10 node timer, at træne i. Node timer er det man betaler for. Jeg valgte dog kun, at gå med 1 time.
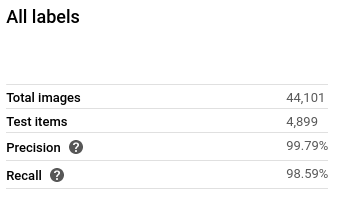
NOTE: Høj “Precision” - rate betyder, at modellen producere færre falske positiver og høj “Recall” - rate betyder, at modellen producere færre falske negativer.
Efter 1,5 times ventetid er den færdig og giver os en præcision på 99,79%. Det er ikke dårligt efter kun 1 times træning, hvor vi ikke specificerede nogle hyperparametre. Nemt at finde ud af når man lige får taget på hele Google Cloud’s måde, at udføre forskellige opgaver på.
Dog er der en ting man kan tune lidt, da man har adgang til en tillids grænse som man kan stille på.

Denne værdi står for forholdet mellem “Recall” og “Precision”.
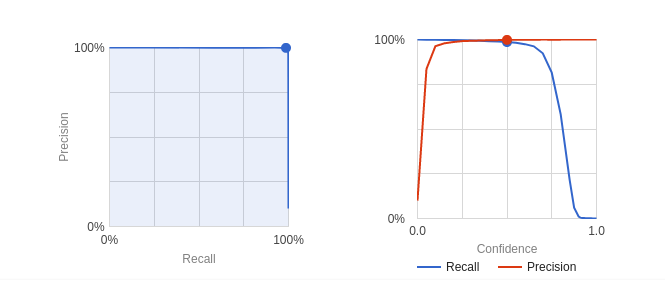
Som kan ses på billedet så har Google fundet et godt punkt, hvor den mener den rammer begge bedst. Man kan afhængig af ens behov indstille denne parameter, da man i nogle situation f.eks. ønsker hellere for mange falske positiver end falske negativer.
Dog blev jeg skuffet over den manglende indsigt i modellen. Da den kun giver præcision og recall raterne samt en Confusion tabel, men ikke nogle hyperparametre eller indsigt i selve modellen. Heller ikke nogle former for algoritme den har brugt. Lidt ærgerligt, hvis man prøver, at lære mere om det, dog underordnet for markedsfolk og analyse folk, som bare skal have hurtige og gode svar.
Modellen i produktion
Google Vision tilbyder selvfølgelig direkte overførsel af modellen over i Google Cloud, så den indenfor kort tid kan benyttes i produktion. Dog tilbyder de også, at man kan downloade modellens container image, som giver mulighed for, at man selv kan køre modellen lokalt eller på egne server, eller en anden cloud udbyder som Google ikke tilbyder direkte overførsel til, hvis det er det man ønsker.
Kilder
Uploading objects
https://cloud.google.com/storage/docs/uploading-objectsAdministering Transfer for on-premises agents
https://cloud.google.com/storage-transfer/docs/managing-on-prem-agentsAutoML Vision Pricing
https://cloud.google.com/vision/automl/pricing#icn-training-examplePrerequisites and Pre work
https://developers.google.com/machine-learning/crash-course/prereqs-and-prework
Andet
- Upload multiple files to GCS using single call to Java API
https://stackoverflow.com/questions/53680768/how-to-upload-multiple-files-to-google-cloud-storage-in-a-single-call-using-java