
ML.NET - Framework
Erfaringer med brugen og eksperimenter i ML.NET.
Hvad er ML.NET?
ML.NET er et high-level machine learning bibliotek af Microsoft, som gør brug af andre ML biblioteker som Tensorflow og ONNX.
ML.NET har også en anden funktion som svare lidt til Google’s Vision som prøvet, at finde den mest effektive algoritme, nemlig AutoML. AutoML prøver, at bruge en række forskellige algoritmer med forskellige parametre og træner lidt på dem for, at se hvad der giver det bedste resultat. Når den er færdig efter den tid man har givet den, så kommer den tilbage med en liste af de bedste algoritmer den fandt til jobbet.
ML.NET er lige nu i Preview som giver lidt udfordringer hen af vejen, samtidig med, at dokumentationen kan være lidt manglende, da ikke alle brugs måder er tænkt efter, enten pga. det ikke er udbredt eller fordi understøttelse først kommer senere. Dette problem stødte jeg desværre ind i.
Brugen af ML.NET
Jeg startede med, at følge deres 10 minutters “Getting started” - guide. Da jeg ville forsøge mig med deres AutoML for, at se hvad den ville gøre med den billede data jeg havde.
Det første jeg gjorde var, at prøve at definere hovedmappen til bilederne, men jeg finder så ud af, at ML.NET forventer en, hvis mappestruktur til billederne. Så billederne skal ligge i en mappe med en undermappe per mærkat eller klasse. Og nede i de undermapper skal de dertilhørende billeder så ligge.
Microsoft giver selv dette eksempel:
\---flower_photos
+---daisy
| 100080576_f52e8ee070_n.jpg
| 102841525_bd6628ae3c.jpg
| 105806915_a9c13e2106_n.jpg
|
+---dandelion
| 10443973_aeb97513fc_m.jpg
| 10683189_bd6e371b97.jpg
| 10919961_0af657c4e8.jpg
|
+---roses
| 102501987_3cdb8e5394_n.jpg
| 110472418_87b6a3aa98_m.jpg
| 118974357_0faa23cce9_n.jpg
|
+---sunflowers
| 127192624_afa3d9cb84.jpg
| 145303599_2627e23815_n.jpg
| 147804446_ef9244c8ce_m.jpg
|
\---tulips
100930342_92e8746431_n.jpg
107693873_86021ac4ea_n.jpg
10791227_7168491604.jpg
Som er et eksempel med nogle blomsterbilleder.
Men jeg har kun alle 49000 billeder i en mappe og en csv fil der passer til. Så jeg undersøgte, hvordan jeg nemt kunne sortere disse billeder.
Jeg kodede så et Python script, som tager en csv fil og finder billednavnet i rækken og sortere dem efter mærkaterne.
Efter så at have kørt mit script. Prøvede jeg så, at definere mappen med og uden csv fil. Det virkede heller ikke.
Efter en del søgen inde i Microsofts ML.NET dokumentation og deres samples repository på GitHub. Fandt jeg noget jeg måske kunne bruge. Det var deres “MulticlassClassification_AutoML” eksempel. Hvor jeg ved et tilfælde så, at de brugte en 64 klasser og en label, da de bruger index i csv filen til, at sige, hvor meget er input og hvor meget er mærkat.
Dette kan ses nedenunder, hvor de i TextLoader definere indekset af mærkaten og datatypen.
var trainData = mlContext.Data.LoadFromTextFile(path: TrainDataPath,
columns : new[]
{
new TextLoader.Column(nameof(InputData.PixelValues), DataKind.Single, 0, 63),
new TextLoader.Column("Number", DataKind.Single, 64)
},
hasHeader : false,
separatorChar : ','
);
Og i deres csv står et billede som følgende.
0,0,5,13,9,1,0,0,0,0,13,15,10,15,5,0,0,3,15,2,0,11,8,0,0,4,12,0,0,8,8,0,0,5,8,0,0,9,8,0,0,4,11,0,1,12,7,0,0,2,14,5,10,12,0,0,0,0,6,13,10,0,0,0,0
Jeg lavede også derfor et script til, så jeg kunne fjerne sorteringen af billederne, så de var tilbage som før.
Så nu skulle jeg bruge en måde, at lave mine billeder om til den her format i en csv. Men det gjorde jeg næsten på en måde i mit originale script i KerasNumberRecognition. Så jeg tog noget inspiration derfra og prøvede, at lave det om til linjer med 785 kolonner (28x28 billede = 784 + 1 til mærkaten). Der var en masse besvær med, at omforme arrays til de rigtige dimensioner. Efter en del Python dokumentation havde jeg kodet dette.
Koden indlæser csv filen og laver billederne flade og om til den rigtige størrelse array, samt dividere dem, deler dem op i TRAIN og VAL sæt og smider dem til sidst i en csv fil med mærkaten.
Jeg fejlede første gang jeg forsøgte, at træne på min data, da den ikke kunne få en høj præcision. Grundet var jeg ikke første gang havde holdt mig til 2 kolonner, en til datapunkterne og en til mærkaten. Det gjorde så, at det første datapunkt var en streng med comma separeret tal. Dette fungerede ikke ret godt. Jeg har samtidig også valgt, at dele sættet på i TRAIN og VAL for den har noget, at validere med efterhånden som den træner.
Jeg startede AutoML med denne kommando: mlnet auto-train -d train_images.csv -v val_images.csv -i 784
Og boom det gav resultater!
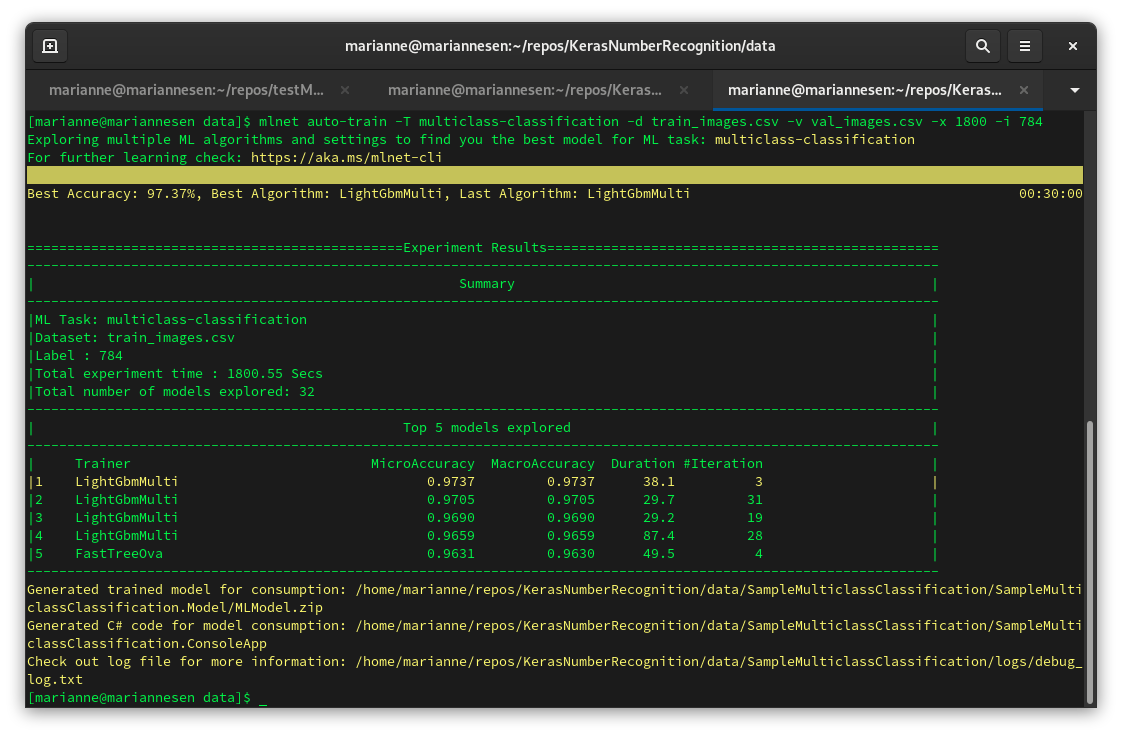
Efter at have givet op på AutoML og var begyndt på, at omdanne deres eksempel kode, kom jeg i tanke om, at man i AutoML kunne definere indekset for csv filerne eller datasættene som de kalder det. Så det gjorde jeg i stedet med et indeks på 784 for mærkaterne.
Så 97,37% på den bedste algoritme efter en halv time, er slet ikke dårligt.
Begrænsninger ved ML.NET og AutoML
Ifølge et oplæg på en issue på dotnet/machinelearning Githubben.
— Great question. GPUs are excellent for accelerating DNN training and inference. Currently we do not offer DNN learners. At this point, we do not have GPU-accelerated components available. However, ML.NET is a general-purpose machine learning framework. It can support a variety of machine learning algorithms, including neural nets such as Cognitive Toolkit (CNTK). Adding support for leading DNN packages within ML.NET is on our roadmap. We will likely support GPU training and inference in the future for specific learners and transforms that can benefit from it.
Så hvis man går ud fra dette svar, så har ML.NET ikke rigtig understøttelse af neurale netværk og deep learning, dog har de lidt. Men ud fra vores testresultater kan vi se, at det ikke er lige så effektivt som det neurale netværk vi lavede i KerasNumberRecognition projektet. Og det neurale netværk var mere effektivt, samtidig med det var et standard MLP der ikke nødvendigvis er lige så godt til billede håndtering som f.eks. CNN.
Konklusion
Jeg kan ud fra mine forskellige eksperimenter og undersøgelser konkludere, at ML.NET nok ikke er det bedste, at køre til vores udfordringer, da de mangler deep learning understøttelse til dels samt, at de kan mangle en række andre features.
Lige nu synes jeg, at Keras og Tensorflow virker bedst pga. de har mere dokumentation og en større brugerbase, så der kan være mere hjælp, at hente. Samtidig ligner det, at TensorFlow og Keras tilbyder mere funktionalitet og er et mere modent framework. Dog ved ML.NET er der AutoML til, at hjælpe en med, at komme i gang, hvor den generere et projekt ud fra den algoritme den fandt bedst. Dette kan tilbyde hurtigere prototyper end Keras.
Kilder
Microsoft
ML.NET - Get started in 10 minutes
https://dotnet.microsoft.com/learn/ml-dotnet/get-started-tutorial/introLoad data into Model Builder
https://docs.microsoft.com/en-us/dotnet/machine-learning/how-to-guides/load-data-model-builder#set-up-image-data-filesMachine Learning at Microsoft with ML.NET
https://arxiv.org/pdf/1905.05715.pdfML.NET CLI Command reference
https://docs.microsoft.com/en-us/dotnet/machine-learning/reference/ml-net-cli-referenceAutomate model training with the ML.NET CLI
https://docs.microsoft.com/en-us/dotnet/machine-learning/automate-training-with-cliML.NET Machine Learning samples
https://github.com/dotnet/machinelearning-samplesML.NET Getting started Multi class Classification AutoML sample
https://github.com/dotnet/machinelearning-samples/tree/master/samples/csharp/getting-started/MulticlassClassification_AutoMLML.NET Community Samples
https://github.com/dotnet/machinelearning-samples/blob/master/docs/COMMUNITY-SAMPLES.md
Numpy
- Transpose
https://docs.scipy.org/doc/numpy/reference/generated/numpy.transpose.html?highlight=transpose#numpy.transpose - Stack
https://docs.scipy.org/doc/numpy/reference/generated/numpy.stack.html#numpy.stack - Hstack
https://docs.scipy.org/doc/numpy/reference/generated/numpy.hstack.html - Concatenate
https://docs.scipy.org/doc/numpy/reference/generated/numpy.concatenate.html#numpy.concatenate - Reshape
https://docs.scipy.org/doc/numpy/reference/generated/numpy.reshape.html?highlight=reshape - Flatten
https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.flatten.html
Andet
- Conversion og list to 2D array
https://stackoverflow.com/questions/21046417/python-conversion-of-list-of-arrays-to-2d-array String to 2D numpy array
https://stackoverflow.com/questions/34401709/convert-string-to-2d-numpy-arrayPandas Data frame
https://www.tutorialspoint.com/python_pandas/python_pandas_dataframe.htmML.NET GPU Support
https://github.com/dotnet/machinelearning/issues/86Reading CSV files in python
https://pythonspot.com/reading-csv-files-in-python/Python create directory if does not exist
https://www.tutorialspoint.com/How-can-I-create-a-directory-if-it-does-not-exist-using-PythonCreate a nested directory safely in Python
https://stackoverflow.com/questions/273192/how-can-i-safely-create-a-nested-directory- List alle files of a directory using Python
https://stackoverflow.com/questions/3207219/how-do-i-list-all-files-of-a-directory