
Long Short Term Memory(LSTM)
Ifølge seneste gennembrud er LSTM blevet observeret som den mest effektive løsning på time series problemer. Altså problemer, hvor rækkefølgen betyder noget. Givet en række data og så forudsige næste data i den række f.eks.
LSTM har en fordel over konventionelle feed-forward neurale netværk sådan som MLP, hvor dataene er skubbet fra input til gemte lag til output (feed forward) og så noget back propagation til, at optimere netværket. Men LSTM har også en fordel over RNN, da LSTM har evnen til, at vælge, at huske mønstre i lange perioder.
Begrænsninger ved RNN
Hvis man f.eks. vil forudsiger en akties pris, så vil man ved en konventionel feed-forward NN model have svært ved, at tage tid med i dens overvejelser, da ved sådan et netværk vil den se alle scenarier som individuelle isoleret scenarier, og derfor ikke tiden med. Så ved f.eks. ved en akties pris, der er det ikke kun åbningsprisen eller volumen af aktien, men også tidligere dages pris aka. trenden.
Så bruger vi da bare RNN? Ja man ville godt kunne løse det med RNN. Men man ville hurtigt løbe ind i problemer ved længere trends eller sammenhænge, da RNN ville fungere, men kun i det korte løb, da tidligere inputs features vil blive mindre og mindre pga. den måde den tager tidligere time steps med i dens beregning.
Så RNN er rigtig effektive til korte sammenhæng. Men hvis vi skal bruge en tidligere væsentlig værdi, så har den glemt det pga. Vanishing Gradient problemet. Det samme ved feed forward. Da ved feed forward NN’s der er aktiverings funktionens afledte værdier som er i fejl funktionen ganget flere gange efterhånden som vi bevæger tilbage mod input laget, fordi et givet lags fejl er et produkt af tidligere lags fejl. Det gør, at de første lag ville være svære, at træne da gradienten ikke længere er særlig tydelig.
Så RNN husker kun kortvarigt. Men det kan fikses ved, at bruge en modificeret version af RNN som er LSTM.
Forbedringer over RNN
Når RNN tilføjer ny information, så transformere den egentlig alt informationen, da den bare køre en funktion på det nye input og det gamle. Dvs. at det hele bliver transformeret. Så RNN tager ikke højde for vigtigheden af det input den får og skære alt over samme kan.
LSTM er i form af celler som data flyder igennem. Disse celler har en tilstand. Men disse celler har også informationer om sidste celles tilstand og sidste celles gemte tilstand samt det nuværende input i time steppet. Dette giver LSTM mulighed for via. dens 3 porte i cellen, at differentiere mellem vigtigt og mindre vigtigt. Så de modificere kun dataene en smule i stedet for det hele og kan derfor vælge, at glemme eller huske forskellige ting.
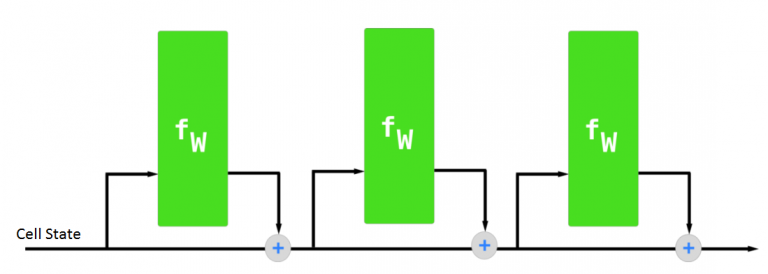 Man kan tænke på det lidt ligesom et samlebånd, hvor dataene flyder fra den ene ende til den anden.
Man kan tænke på det lidt ligesom et samlebånd, hvor dataene flyder fra den ene ende til den anden.
Arkitekturen af LSTM
Som nævnt tidligere består en LSTM celle af 3 porte, forget, input og output portene.
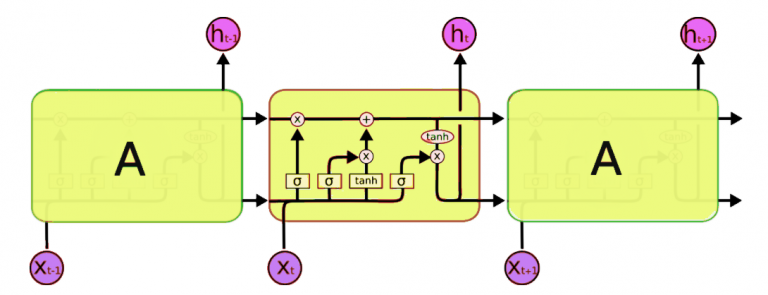 Som kan ses her er der 2 baner som køre igennem. Hvor der kommer et input til cellen og et output fra cellen.
Som kan ses her er der 2 baner som køre igennem. Hvor der kommer et input til cellen og et output fra cellen.
Forget porten som er den første port sørger for, at sortere information fra som ikke længere er nødvendige via. et filter. Dette er nødvendigt for, at optimere ydeevnen af LSTM.
Input porten står for, at tilføje information til cellens tilstand. Input porten kan deles op i 3 trin:
- Regulering af værdierne ved brug af en sigmoid funktion. Dette er cirka det samme som forget porten og filtrere information fra tidligere celles output og det nuværende output.
- Brug af en tanh funktion til, at lave en vektor med alle de mulige værdier der kan tilføjes ud fra tidligere celles tilstand og nuværende input.
- Gange regulerings filtret med vores vektor for så, at tilføje kun den nyttige information i stedet for redundant information.
Output porten står for, at udvælge brugbar information fra cellens tilstand og vise det som et output. Dette er igen 3 trin:
- Laver en vektor efter, at have brugt tanh funktionen på cellens tilstand for, så værdierne er skaleret fra -1 til +1.
- Laver et filter ud fra tidligere celles stadie og nuværende input ved brug af sigmoid til, at regulere vektoren fra trin 1.
- Gange filteret med vektoren og smide det ud som output, men også ud til næste celles gemte tilstand.
Brugen af LSTM
Jeg valgte, at følge en guide, hvor man fik LSTM til, forudsige næste bogstav i macbeth. Jeg brugte en række print funktioner for, at følge med i, hvad der skete. Og jeg eksperimenteret med, at ændre lidt forskelligt f.eks. shapes.
Disse eksperimenter var gode for, at jeg kunne forstå, hvad der skete. Så jeg fjernede lidt, tilføje lidt, lavede lidt ændringer for at se, hvad der skete.
Kilder
- Introduction to Long Short Term Memory
https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/ - Tensorflow Keras Layers LSTM
https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM?version=nightly - Understanding slicing in Python
https://stackoverflow.com/questions/509211/understanding-slice-notation - Python Range
https://www.w3schools.com/python/ref_func_range.asp - Tensorflow Keras Layer
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Layer?version=nightly Introduction to Recurrent Neural Networks
https://www.analyticsvidhya.com/blog/2017/12/introduction-to-recurrent-neural-networks/Nvidia Container Runtime
https://developer.nvidia.com/nvidia-container-runtimeBuild TensorFlow input pipelines
https://www.tensorflow.org/guide/data- Google Cloud AutoML
https://cloud.google.com/automl/ - Regular Expressions Cheat Sheet
https://cheatography.com/davechild/cheat-sheets/regular-expressions/ - TPUs vs GPUs for Transformers(BERT)
https://timdettmers.com/2018/10/17/tpus-vs-gpus-for-transformers-bert/ - My Experience and Advice for Using GPUs in Deep Learning
https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/ - Tensorflow Use a TPU
https://www.tensorflow.org/guide/tpu