
LSTM Netværk til Projektet
Efter, at have fået lidt styr på LSTM og have eksperimenteret med det, gik jeg i gang med, at prøve, at implementere en model for, at kunne analysere på den data vi får fra vores PO.
Netværket skal kunne forudsige / estimere, hvor mange dage der til et vedligehold, så kunden kan se, hvornår de skal regne med, at lave vedligeholdelse på en given maskine.
Jeg har allerede testet, hvor effektiv en regressions model er, hvor det bedste gennemsnitlige absolutte tab jeg fik var 3.5, som ikke er godt nok. Da det er gennemsnitligt, så en del af forudsigelserne vil være over 3.5, så det kan være for stor en afvigelse og det er derfor jeg begyndte med Deep Learning med time series / sekvens problemer. Da også RNN ikke var god nok til, at holde styr på længere afhængigheder og vigtig data, da den har vanishing gradient problemet, som LSTM klare bedre.
LSTM opbygningen
Jeg startede med, at undersøge, hvordan jeg skulle fodre mit netværk med data. Jeg fejlede en del gange, da jeg første gang kun fordret den en række af gangen og ikke f.eks. 60 sammenhængende rækker, som er meningen, da det er sekvensen af dataene LSTM håndtere.
Jeg lavede en metode til, at dele dataene op i sæt af 60 rækker per sæt med en target værdi.
Den modtager, hvor lang tid vi vil se tilbage og et form for “offset” som er vores step. Da vi her bestemmer, hvor mange skridt vi skal gå frem for næste sæt. På denne måde kan vi lave mange flere sæt, da jeg førhen delte alle modtagne data op i 60 og fik kun 103 sæt. På denne måde får jeg op til 716 sæt af samme data.
Jeg skalere dataene til mellen 0 og 1. Jeg kalder så den forrige metode jeg skrev for, at få X og y, som er features og target værdier.
Til sidst laver jeg dataene om til typen dataset fra Tensorflow, da det er den nye måde, at håndtere batch størrelse, shuffling af data og datasæt generelt. Så i stedet for, at splitte dataene op i X og y, samt blande dem tilfældigt kan man dele dem også i dataset.
Man bruger repeat til, at man kan supplere data uendeligt.
Jeg definere modellen og efter en del refactoring kom jeg frem til en fin metode til, at kompilere og træne mine modeller, så jeg senere kan have flere modeller uden, at skulle skrive det samme kode flere gange.
Jeg kalder til sidst min metode, så den kompilere og træner modellen.
Eksperimenter
Jeg har eksperimenteret med forskellige LSTM modeller, optimeringsfunktioner og tabsfunktioner for, at finde det der passede bedst.
Ovenover ses de forskellige modeller jeg har eksperimenteret med. De er forskellige dybder og “bredder” som er output dimensionen.
Samtidig har jeg eksperimenteret med 1, 32 og 64 batch størrelser.
I neurale netværk bruger man også nogle gange en nedadgående learning rate, som jeg ikke har eksperimenteret med endnu. Det gør man fordi jo længere modellen er kommet, jo mindre skulle den helst variere efter det. Så man kan kalde de sidste trænings runder for finpudsnings runder. Dette opnår man ved, at sænke learning rate efterhånden som den kommer længere med dens træning, da den så tager mindre og mindre fra dens træning. Jeg har ikke udført dette endnu, da jeg ikke har forsøgt, at træne en model til perfektion eller så godt som den kan være, da jeg stadig er i gang med, at teste forskellige variationer.
Jeg har også eksperimenteret med diverse optimeringsfunktioner som er tilgængelig i Tensorflow og Keras bibliotekerne såsom Adam, Nadam og RMSprop, da jeg læste om lignende problemer der gjorde brug af dem. Indtil videre har Nadam været den bedste aktiveringsfunktion.
Jeg har samtidig givet, hver model 10 epochs, at forbedre sig i eller stoppes træningen af modellen, da det ikke så ikke ligner den forbedre sig yderligere og på den måde undgår vi overfitting og spildte computer ressourcer.
Resultater
Efter forskellige eksperimenter og en smule tuning er jeg kommet frem til nogle resultater.
Tensorboard
Men jeg havde ikke nogen god måde, at præsentere mine fund. Men så fandt jeg Tensorboard som allerede er med i pip installationen af Tensorflow.
For at bruge Tensorboard skal jeg sørge for, at mine modeller generere Tensorboard logs. Dette kan jeg gøre med Callbacks i trænings kaldet for modellen.
Overover kan man se den metoder jeg bruger til, at definere mine callbacks i. Hvor bl.a. Tensorboard logs callback ligger, så vi generere logs som vi kan se i Tensorboard.
Da jeg køre mine modeller i en container for nem GPU support, så skulle jeg have en måde, hvor jeg fik de logs ud og kunne hoste et Tensorboard lokalt på min host computer.
Jeg tilføje en volume til mit run script:
docker build -t lstmexperiment:latest .
docker run -it --rm --gpus all -v /home/marianne/container-data/LSTMdata:/logs lstmexperiment:latest
Volumen er en lokal mappe på min host som bliver monteret som “/logs” i containeren.
Jeg køre så Tensorboard lokalt og definere min log mappe med:
tensorboard serve --logdir LSTMdata
Hvor vidst alt går godt får man en localhost adresse med port, hvor den hoster boardet:
TensorBoard 2.2.1 at http://localhost:6006/ (Press CTRL+C to quit)
NOTE: Hvis man får en error omkring “Duplicate plugins…” som jeg oplevet, så er det nok fordi man har flere versioner af Tensorflow / Tensorboard.
Man tilgår så bare det link med en browser og bliver præsenteret med Tensorflow.
Præsentation af resultater
Grunden til jeg valgte, at bruge tid på, at sætte Tensorboard op var, så jeg nemt kunne sammenligne de forskellige modeller jeg testede. Men også for, at kunne præsentere mine fund overfor PO.
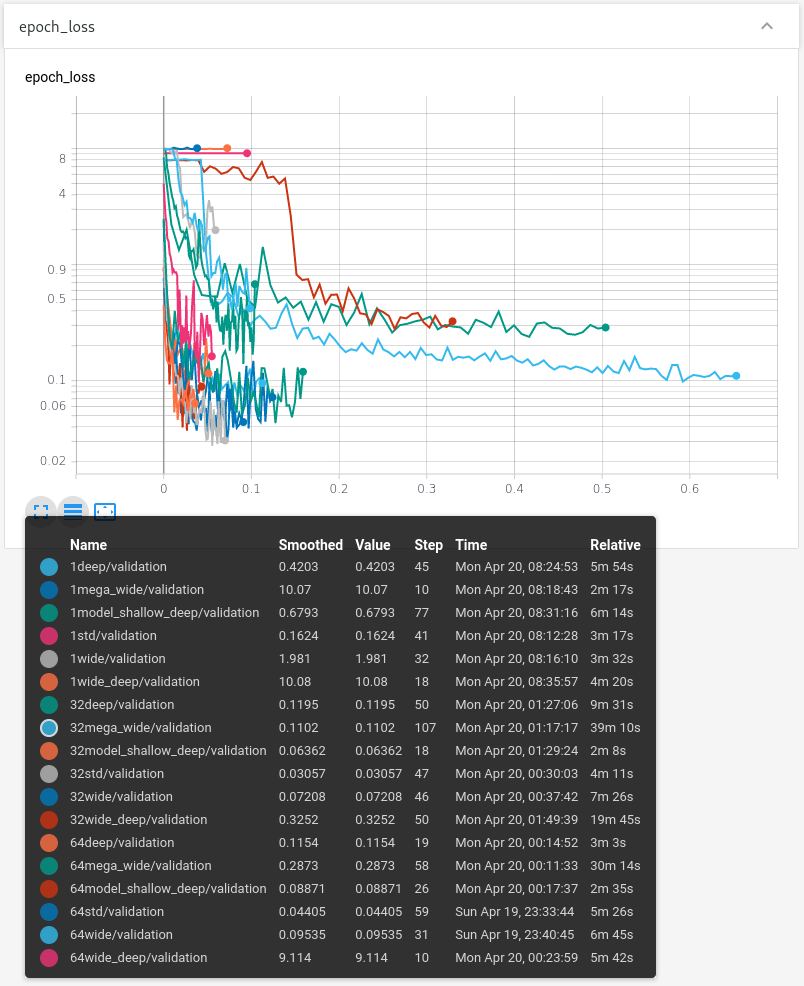
Her kan man se, hvordan de forskellige modeller klarede sig. Nogen dyrere, at træne end andre og nogle meget bedre end størstedelen.
Hvis man så sortere de værst ydende modeller fra.
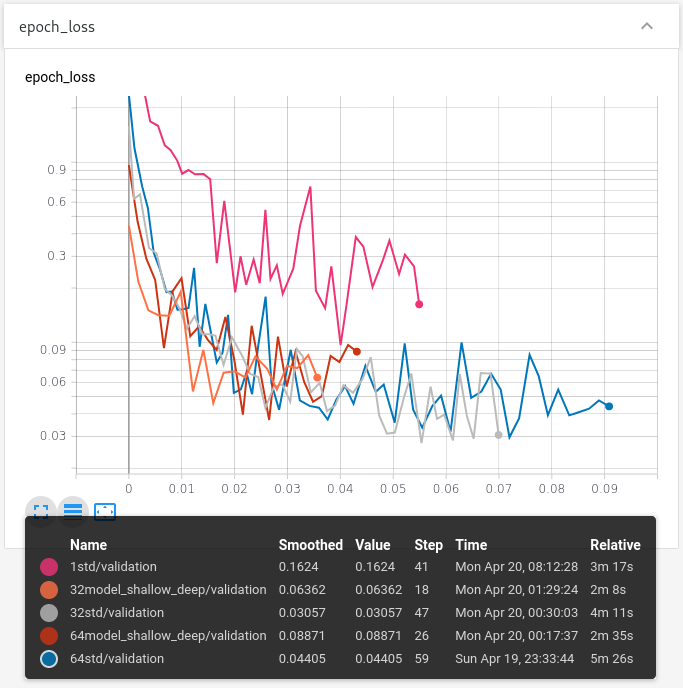
Her har jeg valgt, at beholde den lyserøde model i grafen, da de er min første standard model, så jeg bruger den som et reference punkt for, hvor meget bedre eller værre forskellige modeller er i forhold til den.
Som vi kan se, så er den grå, orange og røde lovende. Men det står i følge disse test mellem den grå og orange, da den røde er den samme model som den orange med en anden batch størrelse og er generelt værre i både træningstid og præcision.
Så hvis vi kigger på den grå og orange så har de, hver deres fordel. Den grå opnår en utrolig præcision, hvor orange opnår en acceptabel præcision, men på næsten den halve træningstid.
PO var ganske tilfreds med det opnåede resultat og snakker om vedligeholdelses intervaller, man måske kan udregne eller ressourceforbrug.
Kilder
- Introduction to Long Short Term Memory
https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/ - Stock Prices Prediction Using ML and DL
https://www.analyticsvidhya.com/blog/2018/10/predicting-stock-price-machine-learningnd-deep-learning-techniques-python/ - Tensorflow LSTM Tutorial
https://www.tensorflow.org/tutorials/structured_data/time_series#single_step_model - Tensorflow Dataset
https://www.tensorflow.org/api_docs/python/tf/data/Dataset?version=nightly - https://www.tensorflow.org/api_docs/python/tf/Tensor?version=nightly
- Keras Cheat Sheet
https://github.com/haribaskar/Keras_Cheat_Sheet_Python - Microsoft Azure Cheat Sheet
https://cdn.analyticsvidhya.com/wp-content/uploads/2017/02/17090804/microsoft-machine-learning-algorithm-cheat-sheet-v6.pdf - Keras Activations
https://keras.io/activations/ - Keras Advanced Activations
https://keras.io/layers/advanced-activations/ - Cheatsheet - Common Machine Learning Algorithms
https://www.analyticsvidhya.com/blog/2015/09/full-cheatsheet-machine-learning-algorithms/ - scikit-learn - Choosing the right estimator
https://scikit-learn.org/stable/tutorial/machine_learning_map/ - Tensorflow Keras Layers LSTM
https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM?version=nightly - Understanding slicing in Python
https://stackoverflow.com/questions/509211/understanding-slice-notation - Python Range
https://www.w3schools.com/python/ref_func_range.asp - Tensorflow Keras Layer
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Layer?version=nightly - Tensorflow Keras Dropout
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dropout?version=nightly - Introduction to Recurrent Neural Networks
https://www.analyticsvidhya.com/blog/2017/12/introduction-to-recurrent-neural-networks/ Importing other Python files
https://stackoverflow.com/questions/2349991/how-to-import-other-python-files- Grid Search for model tuning
https://towardsdatascience.com/grid-search-for-model-tuning-3319b259367e - Practical Recommendations for Gradient-Based Training ofDeepArchitectures
https://arxiv.org/pdf/1206.5533.pdf - Artificial Neural Networks: How can I estimate the number of neurons and layers?
https://www.quora.com/Artificial-Neural-Networks-How-can-I-estimate-the-number-of-neurons-and-layers - Babysitting the learning process
https://cs231n.github.io/neural-networks-3/#baby - Tutorial: Optimizing Neural Networks using Keras
https://www.analyticsvidhya.com/blog/2016/10/tutorial-optimizing-neural-networks-using-keras-with-image-recognition-case-study/#nine - Machine Learning: What are some tips and tricks for training deep neural networks?
https://www.quora.com/Machine-Learning-What-are-some-tips-and-tricks-for-training-deep-neural-networks Rohan & Lenny #3: Recurrent Neural Networks & LSTMs
https://ayearofai.com/rohan-lenny-3-recurrent-neural-networks-10300100899b- NN Overkill?
https://missinglink.ai/guides/neural-network-concepts/neural-networks-regression-part-1-overkill-opportunity/ - NN Activation Functions
https://missinglink.ai/guides/neural-network-concepts/7-types-neural-network-activation-functions-right/ - Artificial Neural Networks: Concepts and Models
https://missinglink.ai/guides/neural-network-concepts/complete-guide-artificial-neural-networks/ - Hyperparameters: Optimization Methods
https://missinglink.ai/guides/neural-network-concepts/hyperparameters-optimization-methods-and-real-world-model-management/