
Datahåndtering 3.0
Jeg valgte, at gå mere væk fra pandas og numpy omkring håndteringen og forbehandlingen af dataene jeg trækker ned. For i stedet, at gå mere over mod Tensorflow’s indbygget funktioner. Men hvorfor?
Problemet med datahåndetering uden for Tensorflow
Tensorflow er evnen til, at kompilere forskellig funktionalitet i “grafer” som de kalder det. Hvor disse grafer kan kompileres og brugeres senere. Men man har også mulighed for, at køre med eager execution, som gør det muligt, at debugge kode fordi, hver funktion bliver evalueret med det samme og har et naturligt kontrol flow, som basalt set er ligesom man kender normal Python eksekvering.
Fordelen ved graferne er, at den ved første gennemgang af en funktion, husker og kompilere den, så den bliver kaldt hurtigere næste gang. Det er selvfølgelig sådan Tensorflow køre deres ting bag kulisserne pga. den højere ydeevne, som betyder en del i machine learning. Dette var mere tydeligt i Tensorflow 1.0, da 2.0 har introduceret en mere naturlig måde, at kode på, da man bare kan kode normal python og sessions samt kompilering af modeller bliver udført ved metode kald.
Fordelen ved Tensorflow’s dataset ud over ydeevne er også kortere kode samt bedre interaktion med Tensorflow biblioteket og TPU understøttelse, da Tensorflow er lavet til GPU og TPU eksekvering og kan gøre effektivt brug af disse resurser. TPU er Google Cloud’s machine learning processorer som er optimeret til matrix beregning.
Brugen af pandas og numpy kan ikke undgås, men det er heller ikke nødvendigt for, at få meget hurtigere håndtering af data. Da man bl.a. også kan putte normale python metoder ind i en @tf.funktion som angiver den som en Tensorflow funktion. Samtidig kan man også kalde python metoder i en dataset.map() funktion, som så bruges på hvert emne i datasættet.
Tensorflow dataset er en stream kompatibel instans. Da Tensorflow streamer datasættet i stedet for det er en liste eller array. Dette gør det derfor muligt, at cache, shuffle, prefetch osv. på sættet, så man nemmere kan styre, hvor meget lagres. Men samtidig har man også mulighed for, at dele dem op i batches og tidsvinduer som også kan gentages, så man egentlig har et uendeligt datasæt, dog med de samme værdier blandet. Men det brugbart i nogen situationer. Tidsvinduer er vores historik / sekvens af data features, hvor batches er hvor mange af disse vinduer / eksempler der skal bruge per. gradient opdatering i netværket.
Batch størrelse er også en faktor i netværkets præcision, da det styre, hvor mange eksempler netværket ser inden den vægter netværket. Dette er f.eks. relevant, hvis man oplever meget ustabil træning, hvor nogle gange ligger tabet højt og andre gange lavt med små spikes, kan man øje stabiliteten ved, at den ser mere variation per. vægtning.
Implementering og bedre brug af tf.dataset
Hvis man kigger på lidt eksempel data her over nedbrud på en dag:
NOTE: Value er antallet af sekunder nedbruddet varede og timestamp er sluttidspunktet for nedbruddet.
Man kan meget hurtigt se, at der ikke rigtig er enighed om hvordan et punkt skal se ud. Da nogle af de gamle punkter f.eks. har sat kommentaren til en kategories nummer og andre har slet ikke kommentarer eller kategorier. Alt dette skulle helst udbedres ligesom i de forrige metoder, hvor jeg forbehandlede dataene.
Jeg startede fra bunden og skrev en ny metode til behandlingen af dataene. Jeg for det meste prøvede, at holde mig til de indbyggede metoder i pandas dataframe samt numpy arrays, da jeg gerne ville undgå de mange loops i den tidligere metode for bedre ydeevne, overskuelighed samt bedre mulighed for, at vedligeholde koden. Det endte også derfor med en del refaktorering.
Jeg startede med, at trække dataene fra PO’s API ind i en Dataframe. Hvor jeg så dropper pointid, da det ikke skal bruges og laver værdierne om til de korrekte typer. Jeg fylder også alle manglende kommentarer med 0, da dette felt er brugt til både kategori numre, men også selve kommentarerne, hvor 0 betyder “Uncategorized” nedbrud.
Da vi gerne vil forudsiger ud fra samlet data per. dag, da det er dage imellem vedligehold vi regner med, så lagde jeg alle disse nedbrud sammen på dags basis. Her kigge jeg på hvornår de har haft planlagt og ikke planlagte reparations nedbrud. Og giver dem 0 for ikke kategoriseret og 1 for førnævnte. På den måde får jeg samlet antallet af nedbrud pr. dag samt den totale nede tid.
Jeg havde over nogle dage arbejdet med datahåndtering og effektivisering af modellen samtidig, hvor jeg løb ind i nogle problemer med modellens præcision grundet, at jeg glemte ting som jeg havde gjort førhen.
Det var bl.a. normalisering af dataene. Man kan se nedenstående hvorfor.
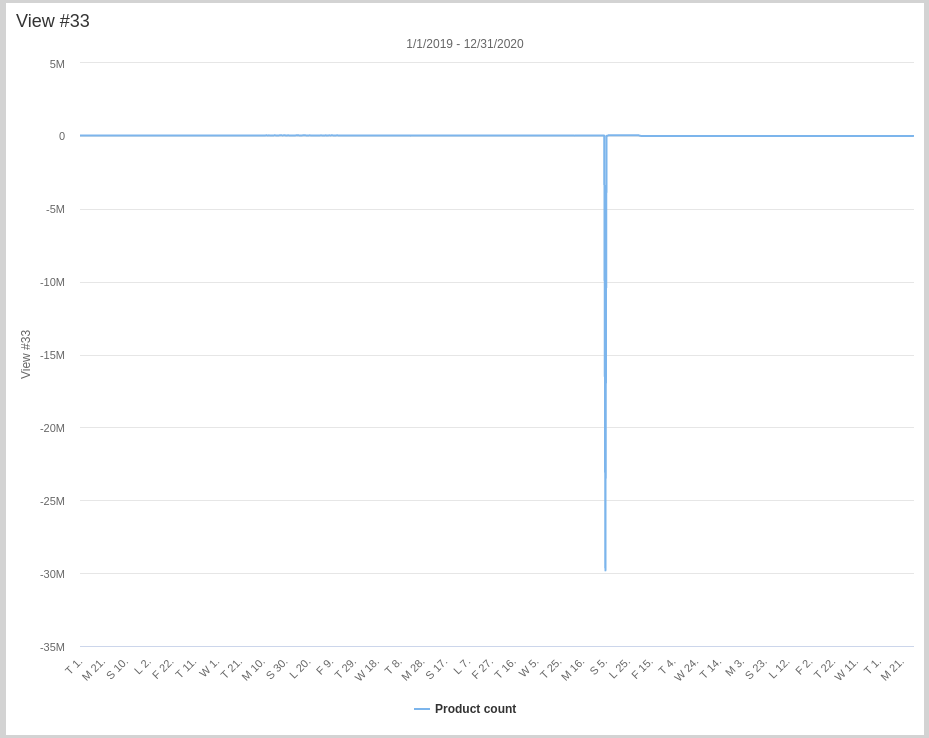
Denne graf viser daglig produktion for de sidste 2 år og sidst jeg tjekkede kan en maskine der normalt producere 887 produkter hvert 15 min. ikke tage næsten 30 millioner produkter ud på en gang. Så der er en tydelig fejl i datene.
Det jeg gjorde var, at for alle punkter under 0 og over 5000 blev sat til NaN, da jeg så kunne tage gennemsnittet i sættet, da NaN værdier ikke tages med i udregning af gennemsnittet i en Dataframe.
Men hvorfor værdier over 5000? Der er jo ikke nogle andre kæmpe udfald ud over den vi har håndteret? Det troede jeg også indtil jeg kiggede på dataene uden det store minus.
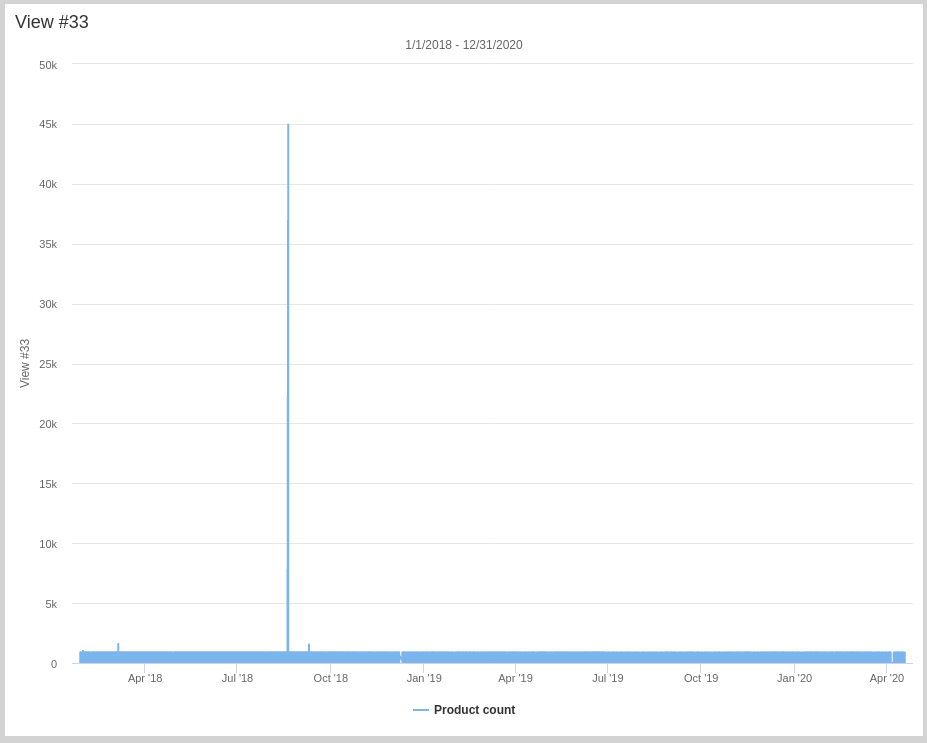
Men hvad er nu det her? Det viser sig, at den på et kvarter produceret 45.000 enheder. Det er lige så usandsynligt som det store minus samtidig med, at tidspunktet var uden for produktionstid, så vidt jeg kan se. Da maskinen godt kan producere på den anden side af 1.500 enheder pr. 15 min. satte jeg grænsen til 5.000, da der umiddelbart ikke er andre udfald.
Jeg beregnede så antallet af dage til næste vedligehold for hver dag. Så nu kom modellens gennemsnitlige absolutte tab ned fra cirka 5 dage til cirka 1,5 dag. En stor forskel meget store udsving med støj kan gøre. Men jeg oplevede stadig et problem. Jeg havde stadig nogle forudsigelser som varierede med 8-33 dage fra det reelle tidspunkt.
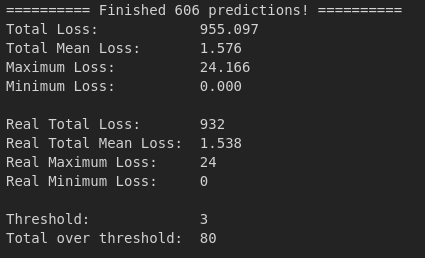
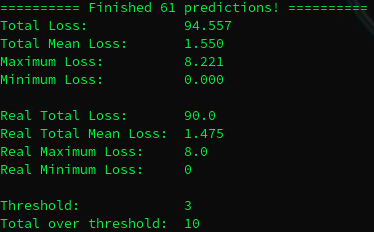
F.eks. ovenover ses det, at det maksimale tab er 8 dage. Og 10 af forudsigelserne er over mit treshold på 3 dage. Den grønne tekst er for data den aldrig har set og hvid tekst for test på hele datasættet.
Jeg prøvede, at øge batch størrelsen, da jeg måske tænkte af nogle af datasættene havde meget kraftige signaler, som måske skulle spredes lidt mellem flere.
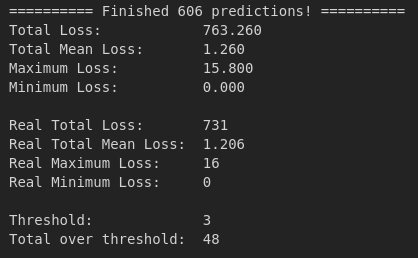
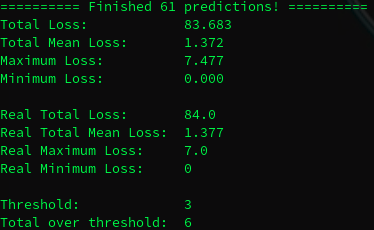
Men selv efter gradvist, at have øget batch størrelsen, så jeg testede med 32, 64 og 128. Så var det bedste med 64 som ses ovenfor. Men ikke meget bedre. Vi skulle helst ned, så ingen forudsigelser skød mere end 3 dage ved siden af og gerne mindre.
Efter nogle dage, hvor jeg havde arbejdet på andre ting og accepteret den store afvigelse indtil videre kiggede jeg på det igen. Jeg fandt en mulig fejl i min datahåndtering, noget som jeg havde tænkt over i tidligere metoder.
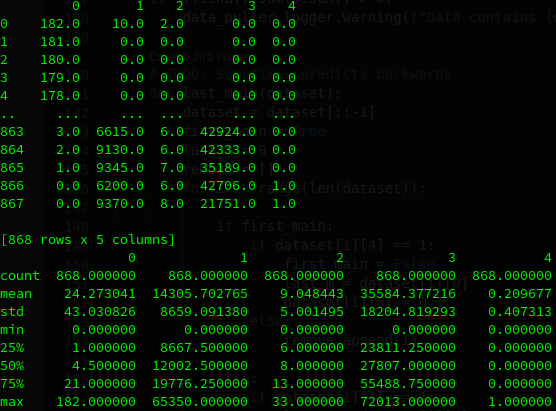
Kolonner: Dage til vedligehold, Nede tid, Antal nedbrud, Produceret på dagen, Vedligeholdelsesdag (0:Nej, 1:Ja).
Hvis man kigger på ovenstående data, så kan man se, at 75% af alle dagene har under 21 dage til vedligehold. Men hvorfor ser vi så dem fra 182 - 178 i række 0 - 4? Det gør vi meget simpelt fordi jeg havde glemt, at fjerne alt den data i starten, hvor der ikke er logget typer af nedbrud. Som gør, at flere sæt på størrelsen af 60 dage, slet ikke har vedligehold før den første gang det ses. Dette håndteret jeg i sidste metode på den måde, at jeg fandt det første vedligehold og det sidste for så, at lave sæt ud af mellemliggende dage. Så det gjorde jeg.
Ovenover tager jeg datasættet og vender om, så jeg starter med nutiden og går bagud, da det er nemmere så, at holde næste vedligehold tidspunkt, da jeg starter med det og går bagud. Jeg sortere også de første dage fra indtil det sidste vedligehold der blev holdt, da de dage efter sidste vedligehold ikke har et kendt tidspunkt for næste vedligehold, da det ikke eksistere endnu. Jeg efterfølgende erstattede alle dage med over 40 nedbrud med et gennemsnit, da nogle dage havde 100 nedbrud som ikke alle var reelle nedbrud.
Jeg smed så datatene ind i en tf.dataset som jeg gjorde før, men behandler selve tidsvinduerne i dem. Jeg skubber hvert vindue en plads pr. vindue og kan derfor lave mange vinduer af 60 dages størrelse.
Hvor det færdige sæt kan ses som:
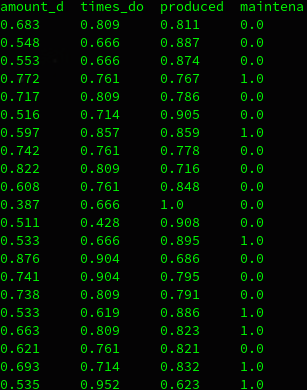
Jeg shuffler, splitter, batcher, cacher og prefetcher så datasættet i min træner. Shuffler med et seed, så den blander dataene på samme vis, hver gang. Splitter for at få validerings og test sæt ud over træningssættet. Batcher for, at den ser flere sæt inden den opdatere / lære af eksemplerne. Cacher for, at dataene blive læst ind i ram ved første brug og holdt der. Caching gør jeg til sidst for, at cache sættet når det er blevet omdannet til batches, så det ikke skal gøre igen. Prefetcher, så næste batch er klar inden den er færdig med den nuværende. Dette er meget godt, hvis man har meget data der skal læses ind. Dog giver det ikke meget her, da sættene ikke er så store, at de ikke kan holdes i ram.
Men til sidst. Taaadaa!
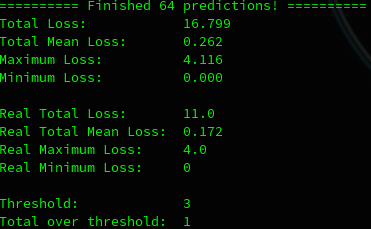
Et meget tilfredsstillende resultat og et bevis på, hvor vigtig korrekt håndtering af data er. Normalt ville den ligge omkring et gennemsnitlig tab på 0,8 og en maksimal afvigelse på 5-6, men jeg har lavet lidt hyperparameter tuning siden, som jeg beskriver i et andet oplæg.
Den har stadig en der går over de 3 dage som vi ønsker, men ikke med meget.
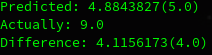
Ovenover ses den ene der var over. Som jeg også har erfaret ved andre test runder med modellen, så forudsiger den før tid i stedet for, for sent. Det er det ønskede adfærd, da vi hellere ser den siger noget før tid, end den siger noget for sent, så det kan gå galt.
Denne data er selvfølgelig vores test data den ikke har set før, så vi får det mest præcise estimat af modellens ydeevne. Modellens gennemsnitlige absolutte tab er virkelig godt som det umiddelbart ser ud.
Kilder
- Multi-worker training with Keras
https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras#preparing_dataset - tf.data.Dataset
https://www.tensorflow.org/api_docs/python/tf/data/Dataset?version=nightly#cache - Adding a dataset
https://www.tensorflow.org/datasets/add_dataset#use_the_default_template - tf.data.Dataset
https://www.tensorflow.org/api_docs/python/tf/data/Dataset?version=nightly - TFRecord and tf.Example
https://www.tensorflow.org/tutorials/load_data/tfrecord?version=nightly - tf.Tensor
https://www.tensorflow.org/api_docs/python/tf/Tensor?version=nightly - pandas Dataframe
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html - numpy delete
https://numpy.org/doc/stable/reference/generated/numpy.delete.html?highlight=delete#numpy.delete