
Hyperparameter tuning og Visualisering
Når man har identificeret sit problem og valgt, hvilken type netværk fungere bedst, samt når man har behandlet sin data, så kommer man til hyperparameter tuning, hvor vi effektivisere modellen.
Hyperparametre er parametre der ikke kan kan læres, men er værdier som er sat ude fra modellen. Det kan f.eks. være, hvor mange gemte lag der er i modellen eller, hvilken optimerings funktion man bruger.
Implementering
Efter noget research på lignende problemer, som min model og netværk løser, og hvad jeg har forsøgt mig med i tidligere eksperimenter som jeg har beskrevet i mit “LSTM til Projektet” oplæg. Så kom jeg frem til lidt forskellige intervaller af parametre som jeg skrev ind i min kode.
Her har jeg 4 forskellige optimeringsfunktioner som jeg har haft nogenlunde held med i tidligere forsøg. Samt har jeg erfaret, at over 4 gemte lag ikke giver gode resultater, det samme med output enhederne når man kommer over 600. Denne forundersøgelse, hvor jeg tager nogle få kørsler med høje eller små værdier, er rigtig god til, at estimere, hvilke intervaller der giver mening, så man ikke køre en masse store modeller igennem som egentlig ikke har nogen chance for, at være bedre.
Men hvor i disse intervaller ligger den optimale kombination? Det får vi maskinen til, at afprøve for os. Så jeg skrev et loop der gik alle kombinationer igennem.
Dette loop bygger så, hver model og træner den.
Jeg har så et callback som indsamler hyperparameter værdierne, så jeg kan se dem senere, men også angiver et tidlig stop, som stopper med, at træne modellen, hvis den ikke har forbedret sig over X antal epochs, som så går tilbage til den iteration med bedste ydeevne og genskaber dens værdier. Jeg har sat patience til 60 epochs, da modellen helst skal nå, at gå over sit optimale punkt, så vi ved den ikke kan yde bedre, da vi som sagt til sidst gendanner ud fra den mest optimale iteration, så vi får den optimale model for de givet parametre.
Callback metoden kaldes fra min metode som træner modellen som også står for, at kalde min model-bygger metode.
Denne model-bygger metode som ses ovenfor tager ganske enkelt vores hyperparametre og laver en model ud fra. Metoden sørger også for, at det sidste lag inden output laget ikke sender udregnet sekvenser med, men kun outputtet, da det kun bruges fra LSTM til LSTM lag. Den returnere så modellen til vore træne metode som kaldte den.
Træner metoden ses nedenfor.
Denne metode er den metode der samler det hele.
Jeg lader så min computer køre igennem de 60 forskellige modeller det bliver til i alt for, at komme igennem alle parametre. Det tager på anden side af 3 timer, så det kan med fordel gøres om natten. For måske senere, at mindske træningstid kan man med fordel optimere yderligere eller bruge en stærkere GPU eller TPU. Mit træningsmiljø gør brug af Tensorflow’s image: tensorflow/tensorflow:nightly-gpu, som har GPU support til nvidia kort.
Resultater
Efter at den har været igennem alle modeller kan vi åbne Tensorboard som kan læse log filerne. Tensorboard kan også køre på samme tid, hvis man ønsker, at se udviklingen live som også godt kan være interessant.
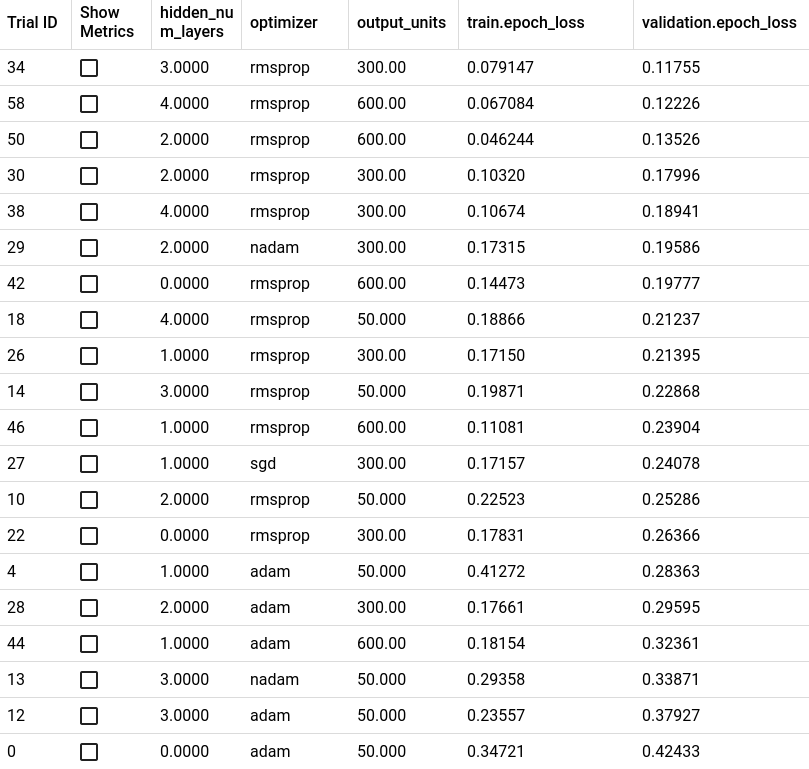
Ovenover ses top 20 over de bedste modeller ud fra validerings tabet. Jeg valgte, at tage top 20, da efter top 20 kommer de fleste modeller over 1 og over 4 i absolut gennemsnitlig tab. Man skal samtidig også tage resultaterne med et gram salt, da modellerne kan klare sig forskelligt mellem hver session.
Vi kan konkludere ud fra vores resultat, at rmsprop som optimeringsfunktion er umiddelbart den bedste med få undtagelser. Vi kan også se, at antallet af gemte lag er bedst omkring 2-4 styks og bredden på de lag ligger omkring 300-600.
Scheduled learning rate og batch size
Resultaterne viser også, at vi ikke har meget overtræning i modellerne, så der vil umiddelbart ikke være en grund til, at ligge et dropout imellem lagene, som man ellers gør for, at undgå overtræning. Dropout gør det, at den deaktivere dele af modellen, så modellen ikke kan lære træningssættet udenad, da den er tvunget til, at lære med forskellige tilfældige dele deaktiveret.
Hvis vi kigger på top 5, vist i forhold til trænings tid.
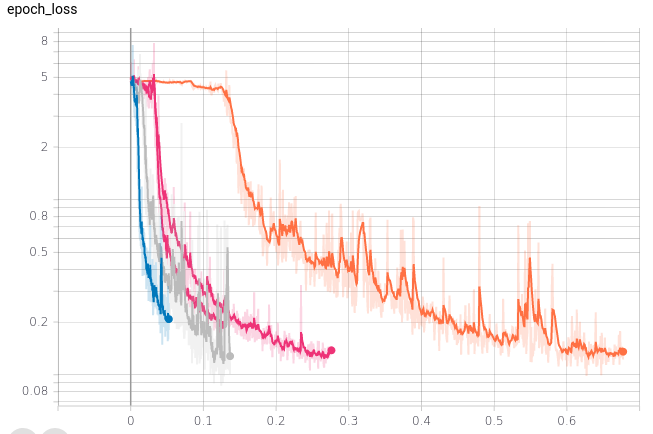
Jeg har jævnet dataene lidt med Tensorboard’s indbygget smoothing funktion, som jeg har sat til 0,8. Grundet til jeg har valgt, at vise i forhold til træningstid er fordi, det samtidig er vigtigt, at tænke på, hvor mange ressourcer man bruger.
Vi kan se en del spikes, da jeg på daværende tidspunkt kun brugte en batch størrelse på 1. Fordi jeg ikke kendte til overførte vægte på daværende tidspunkt. I Keras / Tensorflow har man muligheden for, at træne en model med én batch størrelse for så efter, at overføre de lærte parametre til en anden model, som gør brug af den rigtige batch størrelse. Ens ønsket batch størrelse afhænger af, hvor mange target værdier man har. I mit tilfælde forudsiger jeg 1 tal som er dage til næste vedligehold, så jeg ønsker kun 1 forudsigelse af gangen, så min produktionsmodel skal helst gøre brug af en batch størrelse på 1. Da jeg ellers helst skulle lave 16 forudsigelser af gangen, hvis mine batches havde en størrelse på 16.
For yderligere, at mindske udslag kan man lave en scheduled learning rate, som mindskes over tid. Grunden til det kan være en god idé er, at efterhånden som modellen bliver bedre ønsker man ikke den lære lige så aggressivt som den gjorde i starten. Da den er på mod sit optimale punkt og helst ikke skal afvige yderligere.
Man kan tænke på det lidt ligesom en professionel bokser. En professionel bokser har en god teknik og har trænet boksning længe. Hvis han slår forkert en gang, så tilpasser han ikke sit slag, så drastisk som da han lærte at bokse. Fordi han kender allerede teknikken. Det er derfor ikke nødvendigt, at tilpasse så drastisk, da det vil få ham længere væk fra perfektion, hver gang han ramte forkert. Det samme gælder vores model.
Implementering af Scheduled learning rate
Coming soon TM
Kilder
- Optimize TensorFlow performance using the Profiler
https://www.tensorflow.org/guide/profiler?authuser=1#gpu_kernel_stats - Mixed precision
https://www.tensorflow.org/guide/keras/mixed_precision?authuser=1 - tf.keras.callbacks.TensorBoard
https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/TensorBoard?authuser=1&version=nightly - TensorFlow Profiler: Profile model performance
https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras - Better performance with the tf.data API
https://www.tensorflow.org/guide/data_performance?authuser=1#the_dataset - Save and load models
https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model - Get started with TensorBoard
https://www.tensorflow.org/tensorboard/get_started - tf.keras.Sequential
https://www.tensorflow.org/api_docs/python/tf/keras/Sequential?version=nightly#compile - tf.keras.Model
https://www.tensorflow.org/api_docs/python/tf/keras/Model?version=nightly - Understanding RMSprop
https://towardsdatascience.com/understanding-rmsprop-faster-neural-network-learning-62e116fcf29a - Visualizing Optimization Algos
https://imgur.com/a/Hqolp#NKsFHJb - Tensorboard Debugger Github
https://github.com/tensorflow/tensorboard/tree/master/tensorboard/plugins/debugger - Role of batch size in Keras LSTM
https://stackoverflow.com/questions/48491737/understanding-keras-lstms-role-of-batch-size-and-statefulness - How are inputs fed into the LSTM/RNN network in mini-batch method?
https://www.quora.com/How-are-inputs-fed-into-the-LSTM-RNN-network-in-mini-batch-method?share=1 - How to use Different Batch Sizes when Training and Predicting with LSTMs
https://machinelearningmastery.com/use-different-batch-sizes-training-predicting-python-keras/ - Difference between samples, timesteps and features for LSTM input
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input/ A Gentle Introduction to Mini-Batch Gradient Descent and How to Configure Batch Size
https://machinelearningmastery.com/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/- Multi-worker training with Keras
https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras#preparing_dataset - tf.data.Dataset
https://www.tensorflow.org/api_docs/python/tf/data/Dataset?version=nightly#cache tf.Tensor
https://www.tensorflow.org/api_docs/python/tf/Tensor?version=nightly- Nvidia GPU Problem 1
https://developer.nvidia.com/nvidia-development-tools-solutions-err-nvgpuctrperm-cupti - Nvidia GPU Problem 2
https://developer.nvidia.com/nvidia-development-tools-solutions-ERR_NVGPUCTRPERM-permission-issue-performance-counters